발전이 너무 빨라...
0. 시작하면서
이번 포스팅은 최근 BERT를 능가하여 화제가 된 XLNet outperforms BERT on several NLP Tasks 글을 번역한 내용이 포함되어 있습니다.
1. BERT
BERT는 Bidirectional Encoder Representations from Transformers의 약자로 18년 10월에 논문이 공개됐고, 11월에 오픈소스 코드까지 공개된 구글의 새로운 Language Representation Model이라고 한다. 이 모델은 그간 높은 성능을 보이며 좋은 평가를 받아온 ELMo(Embedding from Language Models, 언어 모델 기반 어휘 임베딩)를 의식한 이름에, NLP 11개 Task에서 state-of-the-art1를 기록했다고 한다.
BERT에 대한 자세한 내용은 추후에 포스팅해서 링크를 걸어놓을 예정.
2. XLNet
여기서부터 블로그를 번역한 내용입니다.
2 Transfer Learning NLP에 사용되는 Neural Network를 사전 훈련하는데 성공한 두 가지 사전 훈련 목표는 3 autoregressive(AR) language modelings와 autoencoding(AE)다.
Autoregressive language modeling은 최근 감정 분석과 물음/질문과 같은 몇몇 다운스트림 NLP Task에서 효과적인 것으로 밝혀진 양방향 컨텍스트를 모델링할 수 없다.
반면에 Autoencoding기반 사전 훈련은 손상된 데이터로부터 원래의 데이터를 재구성하는 것을 목표로 한다. 유명한 예시로 몇몇 NLP Task에서 효과적인 첨단기술(state-of-the-art)인 BERT에서 사용된다.
BERT와 같은 모델의 장점 중 하나는 양방향 컨텍스트(bidirectional context)를 재구성 프로세스에서 사용할 수 있다는 것인데, 이는 AR Language 모델링에는 없는 것이다. 그러나 BERT는 사전 훈련 중에 부분적으로 input data(i.e tokens)를 마스킹하는데, 이로 인해 pre-training-finetune에서 차이가 나는 결과를 보여준다. 게다가 BERT는 예측 토큰에 대한 독립성을 가정하며, AR 모델이 예측 토큰의 공동 확률을 고려하는 제품 규칙을 통해 허용한다. 이것은 BERT에서 발견된 pretrain-finetune 불일치에 잠재적으로 도움이 될 수 있다.
XLNet은 두 가지 유형의 언어 사전 훈련 목표(AR and AE)에서 아이디어를 빌려오면서 그 한계를 회피한다.
The XLNet model
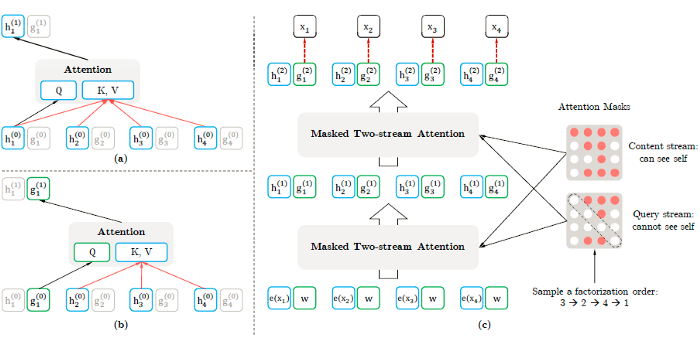
XLNet은 양방향 컨텍스트를 캡처하여 일반화된 order-aware AR Language Model이 될 수 있는 컨텍스트를 좌우 토큰으로 구성할 수 있는 training time동안 permutation operation을 사용한다. 사전훈련 동안, XLNet은 4 Transformer-XL에서 제안된 세그먼트 순환 메커니즘과 상대적인 인코딩 방식을 적용한다.
기본적으로, 새로운 permutation language modeling 목표(추가 세부 사항은 논문을 참조)는 모든 pemuted factorization order들에서 모델 파라미터를 공유할 수 있다. 이를 통해 AR 모델은 BERT가 적용되는 독립성 가정과 pretrain-finetune 불일치를 피하면서 양방향 컨텍스트를 적절히 효과적으로 캡처할 수 있다.
간단히 말하면, XLNet은 원래 시퀀스를 유지하며, positional encoding을 사용하며, Transformers의 special attention mask에 의존해 factorization order의 permutation을 달성한다. 바꾸어 말하면, 원래의 Transformer architecture는 target의 모호함과 pretrain-finetune의 불일치와 같은 문제를 피하기 위해 수정되고 re-parameterize된다.
이 핵심적인 변화는 hidden representation layers(세부사항은 논문을 참조)에서 발생한다. XLNet은 주요 사전훈련 프레임워크로 사용되는 Transformer-XL를 기반으로 한다. 분명히 제안된 permutation 작업이 작동하기 위해, 이전 세그멘트에서 숨겨진 상태들을 적절히 재사용할 수 있는 몇 가지 수정이 제안된다. BERT의 몇 가지 디자인 아이디어는 부분적인 예측을 수행하고, 질문 답변 및 문맥 단락과 같은 multiple segments 으로 구성된 특정 작업을 지원하기 위해서 사용된다.
아래 예에서 볼 수 있듯이, BERT와 XLNet 모두 목표를 다르게 계산하는 것을 관찰할 수 있다. 일반적으로 XLNet은 BERT는 생략시키는 (New, York)과 같이 예측 타겟 간의 더 중요한 종속성을 캡처한다.
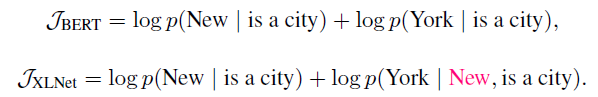
XLNet은 또한 GPT및 ELMo에 비해 더 많은 종속성을 커버한다는 것을 증명한다.
전반적으로, XLNet은 언어 모델링과 사전 훈련 사이의 격차를 해소하기 위해 BERT 및 Transformer-XL과 같은 이전 방법의 AR 모델링 및 차용 기법을 모두 활용하여 달성한 설득력 있는 케이스를 제시한다. 더 중요한 것은, XLNet은 언어 모델이 유용한 일반화를 통해 잠재적으로 다운스트림 task를 개선할 수 있다는 것을 의미하는 pretrain-finetune 불일치를 해결하는 것을 목표로 한다.
참조
- BERT 톱아보기, The Missing Papers
- Autoregressive language modelling, 딥러닝을 이용한 자연어 처리 - 조경현 교수
- XLNet: Generalized Autoregressive Pretraining for Language Understanding — (Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, and Quoc V. Le)
정리하면서
최근 NLP에서 화제가 된 XLNet이 어떤건지에 대해서 알아보기 위해 찾은 포스팅을 읽고나니 모르는 내용들이 많아서 하나하나 차근차근 읽어봐야할 것 같다. BERT 논문과 XLNet 논문을 한 번 읽어보면서 구현해볼 수 있으면 구현해보는 쪽으로 공부를 진행해봐야겠다.
추가적으로 최근에 구현했던 CNN for Sentence classification에서 나는 이 논문이 전하려는 Contribution에 대해 완벽하게 파악하지 못했던 것 같다. 다음번에는 이런 논문을 읽을 때 Contribution을 확실히 알 수 있도록 공부를 해야겠다.
-
state-of-the-art: https://www.stateoftheart.ai/ 에서 어떠한 과제에서 가장 우수한 모델을 제출했을 때, state-of-the-art를 기록했다고 하는 듯 하다. 단어 자체도 ‘최첨단의 기술’ 이라는 의미와 일맥상통 한다. ↩
-
Transfer Learning: 기존의 만들어진 모델을 사용하여 새로운 모델을 만들시 학습을 빠르게 하며, 예측을 더 높이는 방법이다. 이미 잘 훈련된 모델이 있고, 특히 해당 모델과 유사한 문제를 해결시 transfer learining을 사용한다. ↩
-
autoregressive(AR) language modelings: 자기회귀 언어 모델링이라고도 하며, Sequence가 주어졌을 때 문장에게 점수를 부여하는 방법이며, 이전 단어가 주어졌을 때, 다음 단어가 나올 확률들을 전부 곱한 것이다. 이렇게 정의하면서 비지도 학습 문제를 지도학습으로 지도학습으로 바꿀 수 있다. ↩
-
Transformer-XL: https://medium.com/dair-ai/a-light-introduction-to-transformer-xl-be5737feb13 을 참조. 한 번 읽어보자. ↩