![[논문 뽀개기] Subword-level Word Vector Representations for korean](https://img.webmd.com/dtmcms/live/webmd/consumer_assets/site_images/article_thumbnails/other/cat_relaxing_on_patio_other/1800x1200_cat_relaxing_on_patio_other.jpg?resize=750px:*)
한국어를 좀 더 잘 이해시켜보자!
cover photo: https://pets.webmd.com/cats/cat-vaccines
읽기 전에
이 포스트는 박성준 님의 Subword-level Word Vector Representations for Korean 논문을 읽고, 한국어 번역 및 요약, 제 생각을 첨언한 글입니다.
한국어를 위한 임베딩
분산형 단어표현에 관한 연구는 영어와 같이 많이 사용되는 언어에 초점이 맞추어져 있다. 어쩔 수 없는 부분인 것 같다. 많이 사용되는 언어일수록 데이터도 많고 쓰는 사람도 많기 때문에 자연스레 초점이 맞춰질 수 밖에 없는 부분이다.
물론 인공지능 특성상 영어에 초점이 맞추어진 모델을 한국어에도 사용할 수 있다. 하지만 언어 특유의 지식의 차이로 인해 영어에 비해서는 정확도도 떨어질 것이다. 이 논문은 한국어 특유의 지식은 워드벡터 표현의 정확성과 풍부함을 향상시킬 수 있다는 내용을 통해 한국어의 분산 표현을 향상시키는 것을 검토했다. 또한 단어 유사성과 비유를 위한 한국어 테스트 셋을 개발하고 이를 공개했다.
한국어가 가지는 특징
워드 벡터 표현들은 유용한 의미와 통사적 지식이 내장된 많은 코퍼스로부터 만든다. 워드 벡터 표현들은 단어간의 유사성을 측정하는데 사용되어질 수 있고 문서 분류, 대화 모델링, 기계 번역 등 다양한 다운스트림 작업에 적용될 수 있다. 대부분 이전의 벡터 학습 연구는 영어에 초점이 맞춰져 있으며, 따라서 영어와 다른 내부 구조를 가진 언어에 이러한 기술을 직접 적용하는데 어려움이 따르며 한계가 있다.
이런 불일치는 특히 한글과 같이 형태학적으로 풍부한 언어에서 중요한데, 문자 임베딩과 같은 하위어 레벨 임베딩에 의해 형태학적으로 풍부함을 포착할 수 있다. 단어를 하위 단어로 분해하여 입력으로 사용하면 텍스트 분류, 언어 모델링, 기계 번역과 같은 다운스트림 NLP의 성능이 향상되는 것으로 이미 확인되었다. 다양한 언어의 통사적 특징을 포착하는 효과에도 불구하고, 단어를 n-gram 집합으로 분해하고 n-gram 벡터를 배우는 것은 다양한 언어의 고유한 언어 구조를 고려하지 않는다. 따라서 연구자들은 단어 벡터를 학습하기 위해 한자의 하위 구성 요소 및 외부 출처로부터 파생된 통사적 정보(접두사 및 후처)처럼 언어 특유의 구조를 통합한다.
한글의 경우 영어보다 훨씬 엄격하게 정의된 자음과 모음인 jamo-level에서 한국어 구조를 통합하는 것이 문장 파싱에 효과적이라는 것을 보여준다. 이전의 작업은 캐릭터 수준의 분해를 이용한 한국인의 벡터 표현을 개선하는 방안을 검토했지만, 한글은 글자보다 더 작은 단위인 자음과 모음으로 분해될 수 있어 추가 조사의 여지가 있다.
한국어 임베딩 모델
한국어 분해
한국어는 명확한 계층 구조에 의해서 형성된다. 모든 단어는 언어의 자음과 모음을 나타내는 가장 작은 어휘 단위로 분해될 수 있다. 더 유연하게 자음과 모음의 순서로 음절을 구성하는 영어와 달리, 영어의 음절과 비슷한 한국어 ‘문자’는 3개의 자음과 모음이 엄격한 구조로 이루어져있다. 이것들은 문자의 위치에 반영된 이름을 가지고 있다. 1) 초성(syllable onset) 2) 중성(syllable nucleus) 3) 종성(syllable coda). chosung에 있는 접두사 cho는 처음, joongsung의 joong은 중간, jongsung의 jong은 마지막이라는 뜻의 문자다. 각각의 요소들은 이 문자들이 어떻게 발음되어지는지를 가리킨다. 빈 자음을 제외하고, 초성과 종성은 자음이고 중성은 모음이다. 자모는 초성을 위에 두고, 중성은 오른쪽이나 초성 아래, 종성은 바닥에 작성된다.
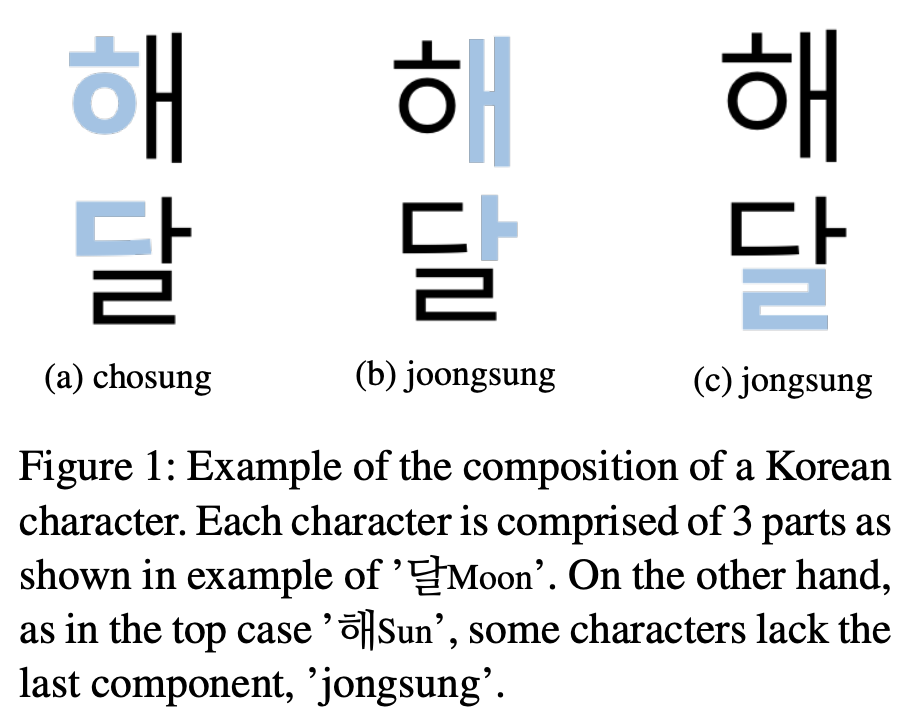
그림 1의 상단에 표시된 바와 같이 ‘해’와 같은 문자는 종성이 없다. 이 경우에, 우리는 항상 세개(자모)를 가질 수 있도록 텅 빈 종성 기호 e 를 추가한다. 그러면, ‘달’은 {ㄷ, ㅏ ,ㄹ}로 분해되고, ‘해’는 {ㅎ, ㅐ, e}로 분해된다.
단어를 분해할 때, 문자의 순서와 자모의 순서를 문자 내에서 유지한다. 이 규칙을 따름으로써, N개의 문자로 이루어진 한국어는 3N개의 자모를 순서대로 가질 것을 보장한다.
마지막으로, 단어의 시작 기호 < 와 마지막 기호 > 은 문장에 추가된다. 예를 들어 ‘강아지’라는 단어는 {<. ㄱ, ㅏ, ㅇ, ㅇ, ㅏ, e, ㅈ, ㅣ, e >}로 분해된다.
자음모음 순서에 따른 N-gram 추출
분해된 한국어로부터 자모 수준과 문자 수준의 n-grams들을 추출한다. 1) 문자 수준의 n-grams 2) 문자 간 자모 수준의 n-grams
이러한 두 단계의 하위단어 특성은 캐릭터가 세 개의 ‘자모’를 가지고 있는지 확인함으로써 성공적으로 n-gram에 통합될 수 있으며, 시퀀스에 빈 종성기호를 추가한다. 더 나은 이해를 위해, 우리는 ‘먹었다’ 라는 단어로 시작한다.
Character-level n-grams 문자를 분해할 때, 빈 종성 심볼 e를 추가하기로 했기 때문에 우리는 분해된 단어의 ‘자모’ 순서에서 단 하나의 문자를 나타내는 jamo-level의 trigrams를 찾을 수 있다. 예를 들어, ‘먹었다’ 라는 단어에서 세 개의 character-level의 unigram이 있다고 하자.
\[\{ㅁ, ㅓ, ㄱ\}, \{ㅇ, ㅓ, ㅆ\}, \{ㄷ, ㅏ, e\}\]그 다음, 우리는 추출된 unigram들을 통해 character-level n-gram을 찾는다. 인접한 unigram들은 n-gram 구성하기 위해 붙여진다. 이 예제에서는 두 개의 character-level bigram들이 있고, 하나의 trigram이 있다.
\[\{ㅁ, ㅓ, ㄱ, ㅇ, ㅓ, ㅆ\}, \{ㅇ, ㅓ, ㅆ, ㄷ, ㅏ, e\}\] \[\{ㅁ, ㅓ, ㄱ, ㅇ, ㅓ, ㅆ, ㄷ, ㅏ, e\}\]마지막으로 우리는 추출된 문자 수준 n-gram 집합에 <과>를 포함한 단어의 총 jamo 시퀀스를 추가한다.
Inter-character jamo-level n-grams 한국어는 교착어이기 때문에, 통시적 문자는 단어의 의미 부분에 부착되며, 이것은 많은\ 변형을 생성한다. 이러한 다양성은 jamo-level 정보에 의해 종종 결정된다. 예를 들어, 조사의 경우 ‘이’나 ‘가’의 사용은 앞의 문자의 종성의 존재에 따라 결정된다. 이런 규칙성을 배우기 위해, 우리는 인접한 문자들 사이에 걸친 jamo-level의 n-grams을 고려한다. 예를 들어 이 예제에는 6개의 inter-character jamo-level trigram들이 있다.
\[\{<, ㅁ, ㅓ\}, \{ㅓ, ㄱ, ㅇ\}, \{ㄱ, ㅇ, ㅓ\}, \{ㅆ, ㄷ, ㅏ\}, \{ㅓ, ㅆ, ㄷ\}, \{ㅏ, e, >\}\]여기서 {ㅇ, ㅓ, ㅆ} 과 {ㄷ, ㅏ, e} 가 포함되지 않은 이유는, 글자들 사이에 걸쳐있는 것이 아닌 한 글자만 분해한 집합이기 때문에 제외한다.
Subword Information Skip-Gram
훈련 corpus에 ${{ \cdots, w_{t-2}, w_{t-1}, w_t, w_{t+1}, w_{t+2}, \cdots }}$ 가 포함되어 있다고 가정하면, Skip-Gram모델은 대상 단어 ${w_t}$ 아래에 있는 문맥단어 ${w_{t+j}}$ 의 로그 확률을 최대화한다.
\[w_t : \frac{1}{T}\sum_{t=1}^T\sum_{-c \le j \le c, j\ne0}^{2c}\log p(w_{t+j} | w_t)\]여기서 c는 컨텍스트 window의 크기, t는 corpus 내의 단어들의 총 개수다. 원래의 Skip-Gram 모델은 위의 로그 ${\log p(w_{t+j} \mid w_t)}$ 에 대해 softmax 함수를 사용하지만, 이는 많은 계산 비용을 요구한다. softmax를 정확하게 계산하지 않기 위해 노이즈 대비 추정에 의해 로그 확률을 대략적으로 최대화하며, binary logistic loss를 사용하여 negative sampling으로 단순화할 수 있다.
\[\text{binary logistic loss}: \log (1 + e^{-s(w_{t+j}, w_t)}) + \sum_{n=1}^{n_c}\log (1+e^{s(w_{t+j, w_n})})\]여기서 ${n_c}$ 는 음의 샘플들의 개수이고, ${s(w_{t+j}, w_t)}$ 는 scoring function이다. 이 함수는 대상 워드 벡터 ${w_t}$ 의 입력과 컨텍스트 워드 벡터 ${w_{t+j}}$ 의 출력 사이의 점곱 연산을 계산한다. Skip-Gram에서 단어 $w_t$ 의 입력이 훈련 corpus에 고유하게 할당되지만, Subword information Skip-Gram의 벡터는 단어에서 추출한 n-gram 집합의 평균 벡터다. 형식적으로 score function ${s(w_{t+j}, w_t)}$ 는 다음과 같다.
\[\frac{1}{\left\vert G_t \right\vert}\sum_{g_t \in G_t}^{\left\vert G_t \right\vert}\mathbf{z}_{g_t}^T \mathbf{v}_{t+j}\]여기서 ${w_t}$의 분해된 n-gram 집합은 ${G_t}$ 이고 이들의 요소들은 ${g_t}$, ${\left\vert G_t \right\vert}$ 는 ${G_t}$ 의 요소 전체 개수이다. 일반적으로 3 ≤ n ≤ 6에 대한 n-gram은 단어의 하위 수준이나 구성성에 관계 없이 한 단어에서 추출된다.
마찬가지로, 우리는 추출된 두 종류의 n-gram을 사용하여 한국어의 벡터 표현을 구성한다. 우리는 jamo-level n-gram의 합, character-level n-gram의 합을 계산하고, 벡터들의 평균을 계산한다. $w_t$ 의 character_level n-gram를 ${G_{ct}}$ 로, inter-character jamo-level n-gram을 ${G_{jt}}$ 로 나타내고, 다음과 같이 score function ${s(w_{t+j}, w_t)}$ 을 얻는다.
\[\frac{1}{N}(\sum_{g_{ct} \in G_{ct}}^{\left\vert G_{ct} \right\vert} \mathbf{z}_{g_{ct}}^T \mathbf{v}_{t+j} + \sum_{g_{jt} \in G_{jt}}^{\left\vert G_{jt} \right\vert}\mathbf{z}_{g_{jt}}^T \mathbf{v}_{t+j})\]여기서 ${z}{g{jt}}$ 는 jamo-level n-gram $ {g_{jt}} $ 의 벡터 표현이고, $ {\mathbf{z}{g{ct}}} $ 는 character-level의 n-gram $ {g_{ct}} $ 의 벡터 표현이다. $ {N} $ 은 character-level n-gram과 inter-charater jamo-level n-gram의 합인 ${\left\vert G_{ct} \right\vert + \left\vert G_{jt} \right\vert}$ 이다.
실험
말뭉치
광범위한 단어를 커버하기 위해 다양한 출처에서 한국어 문서들의 말뭉치를 수집했다. 모델을 교육하는 데 사용되는 말뭉치 다음이 포함된다. 1) 한국어 위키피디아 2) 온라인 뉴스 기사 3) 세종 corpus
이 corpus는 638,708개의 독특한 단어를 가진 1.2억개의 토큰을 포함한다. 우리는 전체 말뭉치에서 10번도 안되는 말을 버린다. 말뭉치에 대한 세부 사항은 표 1과 같다.
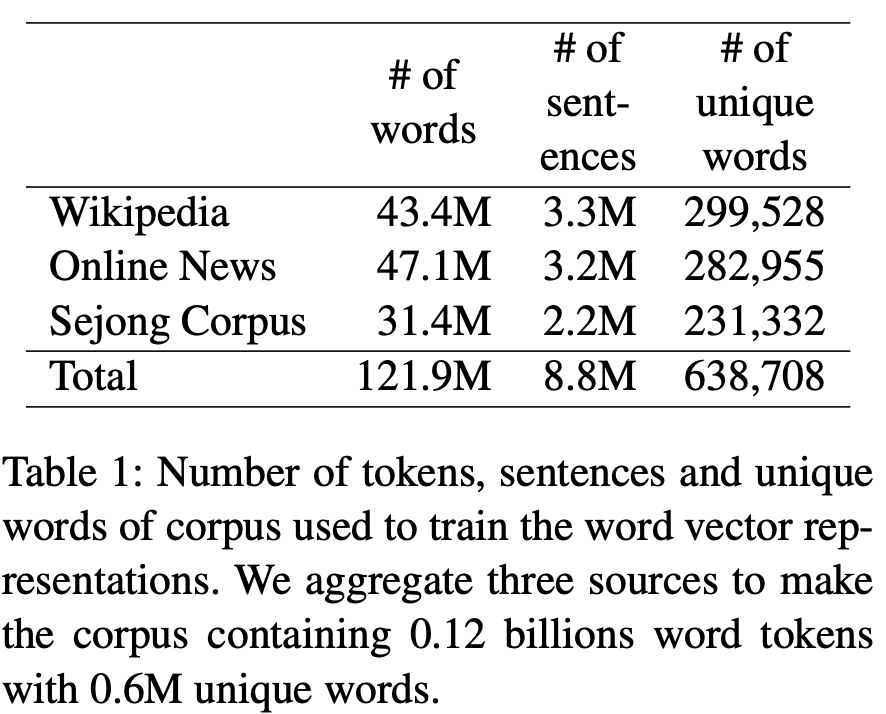
한국어 위키피디아. 먼저 우리는 워드 벡터 표현을 훈련하기 위해 한국어로 된 위키피디아 기사를 선택했다. corpus에는 0.4M개의 기사, 3.3M개의 문장 그리고 43.4M 개의 단어가 포함되어있다. 온라인 뉴스 기사. 우리는 다음 섹션에서 주요 5개 언론사의 온라인 뉴스 기사를 수집했다. 1) 사회, 2) 정치, 3) 경제, 4) 외국, 5) 문화, 6) 디지털. 이 기사들은 2017년 9월에서 11월 사이에 발행되었다. corpus에는 3.2M개의 문장과 47.1M개의 단어가 포함되어 있다. 세종 corpus. 이 데이터는 “21세기 세종 프로젝트”라는 이름으로 수집되어진 공개적으로 사용할 수 있는 corpus다. 이 corpus는 1998년부터 2007년까지 개발되었고, formal한 텍스트(신문, 사전, 소설 등)들과 informal한 text(TV 쇼의 자막, 라디오 프로그램 등)이 포함되어 있다. 따라서, corpus는 위키피디아나 뉴스에서 다룰 수 없는 언어 사용의 주제와 맥락을 다룬다. Pos-tag가 되어있는 문장과 같이 비자연스러운 문장들은 제외했다.
작업과 데이터셋 평가
단어 유사성 작업과 단어 유추 작업을 통해 단어 벡터의 성능을 평가한다. 그러나, 우리가 아는 한 어느 과제에 대한 한국어 평가 데이터 세트가 없다. 따라서 우리는 먼저 평가 데이터 셋을 개발했다. 우리는 또한 감정 분석을 위한 워드벡터도 테스트한다.
단어 유사성 평가 데이터셋
테스트 셋 번역. 우리는 한국어 버전의 단어 유사성 세트를 개발했다. 한국어를 모국어로 사용하는 대학원생 두 명이 WS-353에서 영어단어 쌍을 번역했다. 그 다음, 14명의 한국어 원어민이 서면으로 된 지시에 따라 번역된 쌍에 대해 0에서 10까지 점수를 주어 쌍 사이의 유사성에 주석을 달았다. 원래의 영어로 된 지시는 한국어로도 번역되었다. 각 쌍에 대한 14개의 점수 중 최소 및 최대 점수를 제외하고 나머지 점수의 평균을 계산한다. 번역된 쌍의 원래의 점수와 주석이 달린 점수 사이의 정확도는 0.82이며 이는 변환이 충분히 신뢰할 수 있음을 나타낸다. 우리는 그 차이를 언어와 문화적 차이 탓으로 본다. 우리는 한국어 버전의 WS-353을 공개적으로 사용할 수 있도록 만들었다.
단어 유추 평가 데이터셋
우리는 워드 벡터의 성능을 평가하기 위해 단어 유추 테스트 아이템을 개발했다. 평가 데이터 셋은 10,000개의 아이템 구성되어있고, 5,000개의 의미적 특징과 5,000개의 통사적 특징이 포함되어 있다. 우리는 또한 미래의 연구를 위한 단어 유추 평가 데이터 셋을 발표했다.
의미적 기능 평가. 워드 벡터의 의미적 기능을 평가하기 위해, 우리는 영어 버전의 언어 유추 테스트 셋을 제공한다. 우리는 두 세트의 특징을 모두 다루며, 한글로 번역된 아이템을 다룬다. 아이템들은 Miscellaneous를 포함하여 다섯 개의 카테고리로 분류된다.
- Capital-Country(capt.): 나라 이름과 그 나라의 수도 사이의 관계를 표현하는 두 개의 단어 쌍을 포함한다.
- 아테네Athene : 그리스Greece = 바그다드Baghdad : 이라크Iraq
- Male-Female(Gend.): 남자와 여자 사이의 관계를 평가한다.
- 왕자prince : 공주princess = 신사gentleman : 숙녀ladies
- Name-Nationality(Name) 유명인의 이름이나 스타와 그들의 국적에 대한 관계를 평가한다.
- 간디Gandhi : 인도India = 링컨Lincoln : 미국USA
- Country-Language(Lang.) 국가와 공식 언어 사이의 관계를 평가한다.
- 아르헨티나Argentina : 스페인어Spanish = 미국USA : 영어English
- Miscellaneous(Mics.): 어린 동물들이나, 동물의 소리, 한국 특유의 색깔을 나타내는 단어나 지역 등 다양한 의미적 기능들을 포함한다.
- 개구리Frog : 올챙이tadpole = 말horse : 망아지pony
- 닭chicken:꼬꼬댁cackling=호랑이tiger:으르렁growl
- 파란blue:새파란bluish=노란yellow:샛노란yellowish
- 부산Busan : 경상남도South Gyeongsang Province = 대구Daegu : 경상북도North Gyeongsang Province
통사적 기능 평가. 우리는 다섯개의 대표적인 통사적 카테고리를 정의하고, 기존 카테고리를 원래 세트에 포함하려 하지 않고, 한국 특유의 테스트 아이템을 개발한다. 이 세트의 통사적 특징은 대부분 한국어로 사용할 수 없기 때문이다.
우리는 한국어 언어의 전문적 지식을 가지고 테스트 셋을 개발한다. 다음의 케이스들은 좋은 에제이다. 한국어에서는 목적어 표시가 단어 뒷면에 붙어있고, 다른 사례의 표시들 또한 단어 수준에 명시되어 있다. 여기서 워드 레벨은 ‘그 주위에 두 개의 공백에 의해 범위가 주어진 문구’를 나타낸다. 한국어와 달리 영어에서는 문장의 위치에 따라 목적어가 결정되므로(즉, 주어가 동사보다 먼저 온다), 이 경우에는 단어에 명시적으로 표시되어 있지 않다. 마찬가지로 한국어의 중요하고 독특한 통사적 특징들이 있는데, 이 중에서 우리는 단어 벡터를 평가하기 위해 다음의 다섯 가지 범주를 선택한다.
- Case는 일반적인 명사에 부착된 다양한 사례 표기를 포함한다. 이것은 한국어에서 단어로 표현되는 경우를 평가한다.
- 교수Professor : 교수가Professor+case가 = 축구soccor : 축구가soccor+case가
- Tense는 두 시제의 동사 변형을 포함하며, 그 중 하나는 현재 시제, 다른 하나는 과거 시제다.
- 싸우다fight : 싸웠다fought = 오다come : 왔다came
- Voice는 동사 음성 한 쌍이 있는데, 하나는 능동 음성, 다른 하나는 수동 음성이다. 그것은 언어 접미사로 대표되는 음성를 평가한다.
- 팔았다sold : 팔렸다be sold = 평가했다evaluated : 평가됐다was evaluated
- Verb ending form(동사 마무리 형식)에는 다양한 verb ending form이 포함되어 있다. 다양한 형태는 한국어의 언어 굴절의 일부분이다.
- 가다go : 가고go+form고 = 쓰다write : 쓰고write+form고
- Honorific(Honr.)은 한국어 동사의 형태학적 변동을 평가한다. honorific expression(존댓말)은 한국어에서 다른 언어와 비교하여 가장 구별되는 특징 중 하나다. 이 테스트 셋은 동사에 사용되는 존댓말 ‘-시-‘를 소개한다.
- 도왔다helped : 도우셨다helped+honorific시 = 됐다done : 되셨다done+honorific시
감정 분석
우리는 단어 벡터 평가를 위해 이진 감성 분류 작업을 수행한다. 일련의 단어들을 고려할 때, 훈련된 분류자는 입력 단어의 벡터를 고정시키면서 입력 단어의 정서를 예측해야 한다.
데이터 셋. 우리는 ‘Naver Sentiment Movie Corpus’를 선택했다. 한국 포털 사이트 Naver에서 스크랩했으며, 200k 개의 영화 리뷰를 포함한 데이터 셋이다. 각각의 리뷰는 140자를 넘지 않으며 그것의 감정에 따라 이진 라벨링이 포함되어 있다(1은 긍정, 0은 부정). 양쪽 정서 표본 개수는 긍정 100K개, 부정 100K 합으로 동일하다. 우리는 트레이닝 셋(100k), 검증 셋(25k) 그리고 테스트 셋(25K)을 위해 데이터셋으로부터 샘플링한다. 다시, 각 세트의 감성 계층 비율이 균형을 이루고 있다. 비록 우리는 구두점과 이모티콘을 빼는 간단한 전처리를 적용하지만, 원래의 소스가 포털 사이트의 가공되지 않은 코멘트들이기 때문에 데이터 세트는 여전히 오타, 띄어쓰기 에러 그리고 비정상적인 단어 사용에 대해 문제가 있다.
분류 모델. 감정 분류기를 만들기 위해서 우리는 300개의 hidden unit과 0.5의 드롭아웃 비율을 가진 LSTM 단일 레이어를 채택했다. LSTM unit의 마지막 상태를 고려해볼 때, output 예측을 위해 sigmoid 활성화 함수를 적용한다. 우리는 cross-entropy 손실을 사용하고, 0.001의 학습율로 Adam optimizer를 통해 파라미터를 최적화한다.
비교 모델
우리는 negative sampling에 의해 훈련된 워드레벨, 문자레벨, jamo레벨 Skip-Gram모델을 포함한 비교모델과 우리의 모델의 성능을 비교한다. 각 모델들의 하이퍼파라미터는 단어 유사성 작업을 통해 조정되었다. 우리는 훈련 에폭을 5번으로 고정했다.
Skip-Gram(SG) 우리는 먼저 corpus의 모든 고유 단어에 고유한 벡터가 할당되는 워드레벨의 Skip-Gram 모델과 성능을 비교한다. 우리는 차원의 개수를 300개, negative sampling은 5, window size는 5로 설정했다.
Character-level Skip-Gram(SISG(ch)) 단어를 하위 언어 정보 skip-gram을 기반으로 character-level의 n-gram으로 나눈다. 우리는 차원의 개수를 300개, negative sampling을 5, window size를 5로 설정했다. n은 2-4로 설정했다.
Jamo-level Skip-Gram with Empty Jongsung Symbol(SISG(jm)) 단어를 하위 언어 정보 skip-gram을 기반으로 jamo-level n-gram으로 나눈다. 게다가 종성이 없는 문자일 경우, e 기호가 붙여진다. 우리는 차원의 개수를 300개, negative sampling을 5, window size를 5로 설정한다. n은 3-6으로 설정한다. n=3-6 으로 설정하고 종성 기호를 추가하면 이 모델이 jamo-level n-gram(n=3-6), character-level n-gram(n=1-2)을 포함하는 우리 모델의 특정 사례로 만들어진다.
최적화(Optimization)
우리의 모델을 훈련하기 위해서, 우리는 선형적 학습율 감소와 함께 SGD(stochastic gradient descent, 확률적 경사 하강)을 적용한다. 초기 학습율은 0.025로 설정한다. 학습의 속도를 높이기 위해, 우리는 공유 파라미터와 병렬로 벡터를 훈련하고, 비동기적으로 업데이트된다. 본 모델에서는 character n-gram을 1-4 또는 1-6으로, inter-character jamo-level n-gram은 3-5로 설정한다. 우리는 두 모델을 각각 SISG(ch4+jm)과 SISG(ch6+jm)로 명명한다. 차원은 300, window size는 5, negative sample은 5로 한다. 우리는 우리의 모델을 트레이닝 corpus로 5 에폭동안 훈련시킨다.
결과
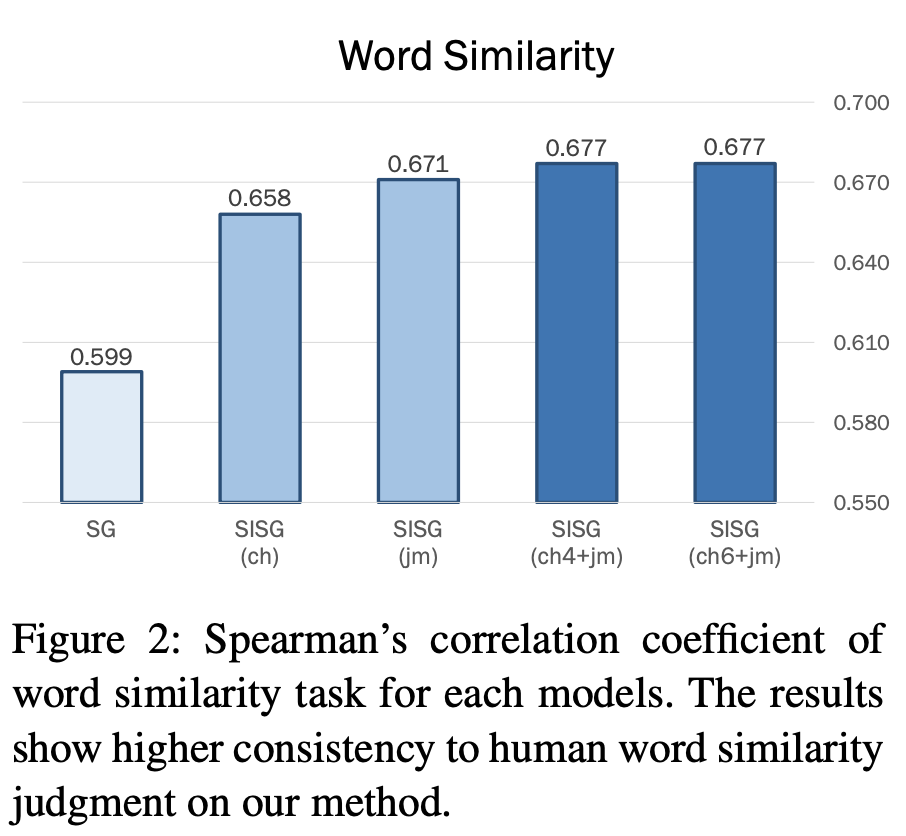
단어 유사성. 우리는 단어 쌍의 유사성에 대한 인간의 판단과 모델의 코사인 유사성 사이의 Spearman의 상관 계수를 보고한다. Fig. 2는 결과를 보여준다. word-level skip-gram에서, Spearman의 상관 계수는 0.599다. 단어 벡터(SISG(Ch))를 구성하기 위해 단어를 character n-gram 으로 분해하면 성능이 0.658로 크게 향상된다. 이것은 단어를 분해하는 것 자체가 형태학적으로 풍부한 언어인 좋은 한국어 단어 벡터를 훈련하는데 도움이 된다는 것을 나타낸다. 게다가 단어가 더 깊은 수준(SISG(jm))레벨로 분해되면, 성능은 0.671로 더욱 향상된다. 다음으로 한국인 특유의 언어적 규칙성을 반영한 jamo 순서에 빈 종성기호 e를 추가하면 단어 벡터의 질이 향상된다. 모델의 특정 사례인 SISG(jm)가 다른 기준선에 비해 높은 상관계수를 나타낸다. 마지막으로 우리가 한 단어로 학습할 character를 4 또는 6으로 늘릴 때, 우리의 모델은 다른 모델들보다 더 뛰어나다.
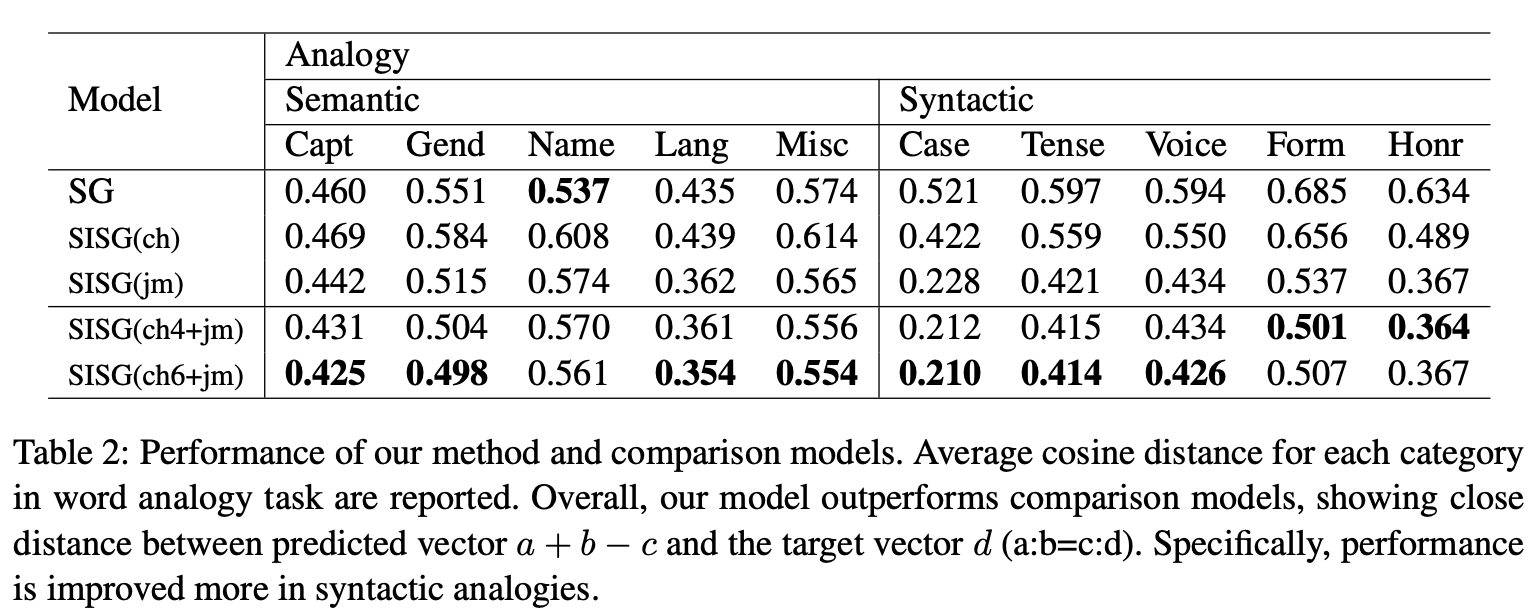
단어 유추. 일반적으로 a:b=c:d 항목과 해당 워드 벡터 ${u_a, u_b, u_c, u_d}$가 주어지면, 벡터 ${u_a + u_b - u_c}$는 벡터와 다른 워드벡터 사이의 코사인 거리를 계산하는데 사용된다. 그 다음, 벡터들은 거리를 기준으로 오름차순으로 정렬되고, 벡터 ${u_d}$가 상단에 있으면 항목이 올바른 것으로 카운트된다. 각 범주의 최상위 정확도나 오류율은 이 작업에 대해 자주 사용되지만, 이 경우 순위기반 측정은 동일한 corpus에 대한 각각의 고유한 n-gram(예: SISG)이나 고유 단어(예: SG)의 전체 개수가 서로 크게 다르기 때문에 측정이 적절하지 못할 것이다. 공정한 비교를 위해 우리는 벡터의 순위를 평가하는 대신 각 범주 별로 벡터 ${u_a + u_b - u_c}$와 ${u_d}$ 사이의 코사인 거리를 직접적으로 기록한다. 형식적으로 a:b=c:d 항목을 지정하면 3COSADD 기반 메트릭을 형성한다.
\[1 - \cos(u_a + u_b - u_c, u_d)\]우리는 각 범주별 예측했던 벡터 ${u_a + u_b - u_c}$와 타켓 벡터 ${u_d}$의 코사인 거리의 평균을 보고한다. 의미적 유사성에서 단어를 문자로 분해하는 것은 의미적 특징을 학습하는 데 거의 도움이 되지 않는다. 그러나, jamo-level n-gram은 전반적으로 의미적 기능에 도움이 되고, 우리의 모델은 기존 모델과 비교해 더 높은 성능을 보여준다. 한가지 예외사항은 Name-Nationality 범주로, 주로 고유 명사를 포함한 항목으로 구성되며, 이들 명사를 분해하는 것은 단어의 의미적 특징을 학습하는데 도움이 되지 않기 때문이다. 예를 들어 간디Ghandi와 인도India의 의미적 특징은 그러한 단어들을 구성하는 character나 jamo n-gram으로 나눌 수 없다는 것은 명백하다.
반면에, 단어를 분해하는 것은 모든 카테고리들에 대한 통사적 특징을 학습하는데 도움이 되고, 더 깊은 수준으로 단어를 분해하는 것은 좀 더 효과적으로 그 특징들을 학습하게 한다. 우리의 모델은 다른 모든 기존의 것들보다 월등히 뛰어나며,word-level Skip-Gram에 비해 감소된 코사인 거리의 양은 의미 범주보다 크다. 한국어는 character-level의 통사적 기호가 단어의 뿌리에 붙여지는 교착어이며, 그것들의 조합은 단어의 마지막 형태를 결정한다. 또한 ‘jamo-level’변환으로 형태를 줄일 수 있다. 이것이 우리가 동시에 단어를 character-level과 jamo-level로 분해하면 한국어 단어의 통사적 특징을 학습할 수 있는 주된 이유다. 우리는 3COSMUL 거리 메트릭을 사용할 때 유사한 성향을 관찰한다.
감정 분석. 우리는 테스트 세트를 통해 이진 감성 분류 작업에 대한 정확도, 손실, 예측, 리콜(recall) 및 f1 점수를 보고한다. 비록 전반적인 퍼포먼스는 동등하나, 단어를 1-6 character n-gram과 3-5 jamo n-gram으로 분해하는 방법은 다른 비교 모델들보다 약간 더 높은 성능을 보여준다. 게다가 우리의 접근은 character-level SISG나 jamo-level SISG과 비교해서 좋은 결과를 보여준다.
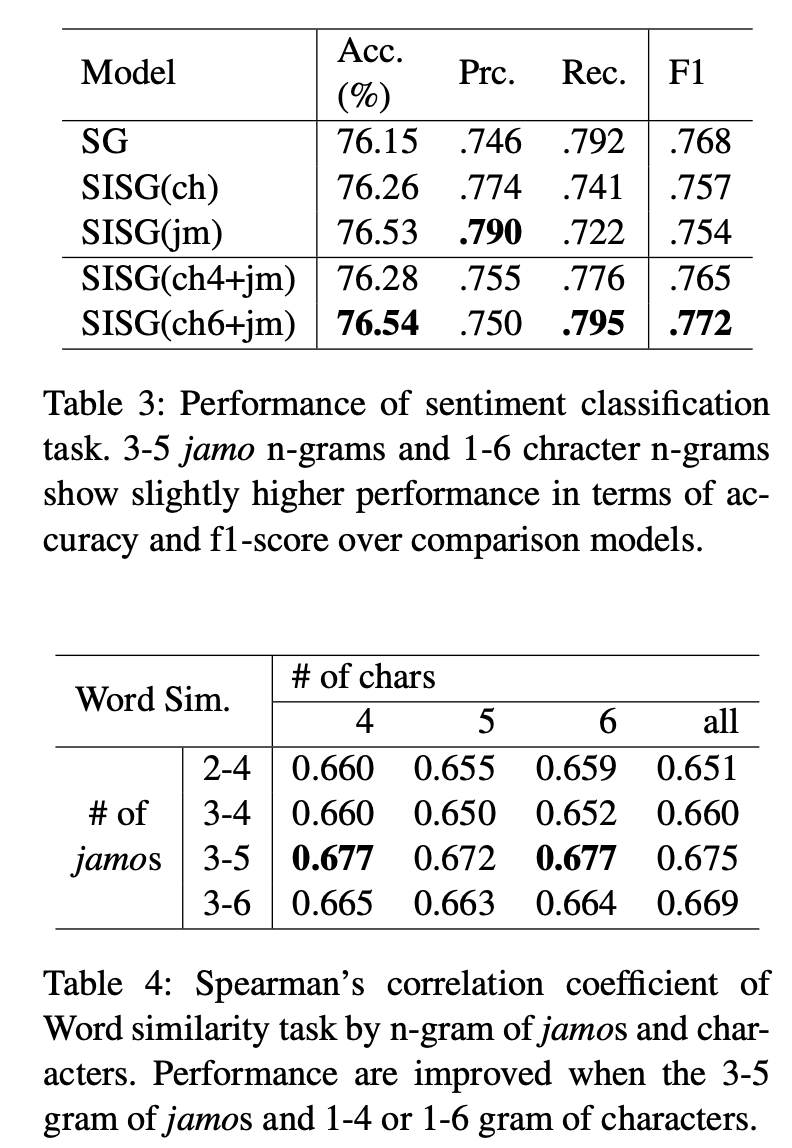
반면에 word-level Skip-Gram은 F1-score에서 우리 모델과 비교할만하다는 것을 보여주며, 심지어 다른 비교 모델보다 더 높다. 데이터셋이 영화나 배우 이름 등의 고유명사를 상당량 포함하고 있으며, 그런 단어들의 의미적 표현은 단어 유추 과제에서 볼 수 있듯이 word-level 표현에 의해 더 잘 포착되기 때문이다.
Effect of Size ${n}$ in both ${n}$-grams. Table. 4는 inter-character jamo-level n-gram과 character-level n-gram의 각 숫자에 대한 단어 유사성 작업의 성능을 보여준다. $n$=5,6개의 n-gram을 포함하여 jamo-level $n$의 경우, bigram을 제외하면 더 높은 성능이 나타난다. 반면, 단어를 분해하는 동안 모든 문자 n-gram을 포함한 문자 수준 n-gram의 n은 성능 향상을 보장하지 않는다. 한국어의 대부분은 6자(전체 corpus의 97.2%) 이하여서, character n-gram에서 n의 최대값 6이 단어 벡터를 학습하기 충분히 큰 것 같다. 또한 4자 이하의 단어는 전체 말뭉치의 82.6%를 차지하므로 n=4 정도도 character n-gram을 학습하기에 충분하다.
결론 및 논의
이 논문에서, 우리는 한국어 문자를 빈 종성 기호가 있는 자모의 순서로 분해한 다음, 그 순서에서 character level n-gram과 intercharacter jamo-level n-gram으로 추출하는 방법을 제시한다. 두 n-gram 모두 n-gram의 평균을 계산하여 단어 벡터 표현을 구성하며, 이러한 벡터들은 subword-level 정보 Skip-Gram에 의해 훈련된다. 벡터의 성능을 평가하기 앞서, 우리는 한국어를 위한 단어 유사성 밑 단어 유추에 대한 테스트 세트를 개발했다. 우리는 단어 유사성 밑 단어 유투 작업으로 이러한 벡터를 평가함으로써 의미적 및 구문적 정보를 포착하는 데 학습된 단어 벡터의 효과를 입증했다. 구체적으로는 자모와 문자 수준 정보를 모두 사용하는 벡터는 교착어에서도 통사적 특징을 더 정확하게 나타낼 수 있다. 게다가 본 연구의 감정 분류 결과는 벡터들의 표현하는 힘이 다운스트림 NLP 업무에 긍정적으로 기여하고 있음을 나타낸다. 한국어 단어를 jamo-level이나 character unigram으로 분해하는 것은 통사적 정보를 포착하는데 도움이 된다. 예를 들어, 한국어 단어는 단어의 뿌리에 문자가 추가한다(목적어 경우의 -‘은’, 과거형을 위한 ‘-었-‘, 존대말의 ‘-시-‘, 음성은 ‘-히-‘, 동사말형태인 ‘고-‘). 그러면 합성어는 ‘되었다’에서 ‘됐다’로 자모 변형을 통해 문자 수를 줄일 수 있다. 이런 이유로, inter-character jamo-level n-gram 또한 그들의 특징을 포착하는데 도움이 된다. 반면에 character-level trigram과 같은 더 큰 n-gram은 그 단어의 더 큰 구성요소가 대부분 그 단어와 함께 발생하기 때문에 그 단어의 고유한 의미를 배울 것이다. 두 가지 기능을 모두 활용하여, 언어적 특성을 반영한 워드 벡터를 효과적으로 생성하여 이전의 워드 레벨 접근 방식을 능가한다. 한국어 단어는 한 번 더 문자소 수준으로 나누어져 주어진 단어에 대한 자모의 순서가 길어지기 떄문에, 우리는 한국어에서 더 깊은 수준의 서브워드 정보의 적용 가능성을 탐구할 계획이다. 한편 우리는 우리의 모델을 노이즈가 있는 데이터보다 더 훈련시키고 그것이 노이즈가 있는 단어들을 어떻게 다루고 있는지 조사할 것이다. 일반적으로 일상적인 한국어 텍스트는 의도적인 오타(‘맛잇다’), 자모로만 이루어진 문자(‘ㅋㅋ’), 띄어쓰기 오류(‘같이가다’) 등이 포함된다. 이러한 오류들이 빈번하게 발생하기 때문에, 실제 단어 데이터를 이용한 NLP 모델의 훈련 벡터를 적용하는 것이 중요하다. 우리는 대화 모델링과 같은 다양한 신경망 기반 NLP 모델에 이러한 벡터를 적용할 계획이다. 마지막으로, 우리의 방법은 jamo와 character n-gram을 통해 한국어의 통사적 특징을 캡처할 수 있기 때문에, POS 태깅 및 파싱 등 다른 과제에 대해서도 같은 아이디어를 적용할 수 있다.