![[논문 뽀개기] KorNLI and KorSTS: New Benchmark Datasets for Korean Natural Language Understanding](https://aplusadvance.com/naver_editor/data/464rg.jpg)
어 없네... 그럼 만들지 뭐
읽기 전에
20년 4월 8일 자로 아카이브에 올라온 뜨끈뜨끈한 논문을 찾았다. 카카오 브레인에서 한국어 자연어 처리를 위한 새로운 데이터 셋을 공개했다는 내용이다. 진짜 멋있는 사람들..
여담이지만 공부할 때 한국어 임베딩을 만드셨던 박규병 님이 보여서 내적 친밀감이 좀 있었다.
Abstract
-
자연어 추론(NLI)와 텍스트의 의미적 유사성(STS)는 자연어 이해(NLU)에서 핵심 과제. 영어나 다른 언어들은 데이터셋이 몇 개 있는데, 한국어로 된 NLI나 STS 공개 데이터셋이 없다.
-
이거에 동기를 얻어 새로운 한국어 NLI와 STS 데이터 셋을 공개한다.
-
이전의 접근 방식에 따라 기존의 영어 훈련 세트를 기계 번역(machine-translate)하고 develop set과 test set을 수동으로 한국어로 번역한다.
-
한국어 NLU에 대한 연구가 더 활성화되길 바라며, KorNLI와 KorSTS에 baseline을 설정하며, Github에 공개한다.
1. Introduction
-
NLI와 STS는 자연어 이해의 중심 과제들로 많이 이야기가 된다. 이에 따라 몇몇 벤치마크 데이터셋은 영어로 된 NLI와 STS를 공개했었다. 그러나 한국어 NLI와 STS 벤치마크 데이터셋은 존재하지 않았다. -> 대부분의 자연어 처리 연구가 사람들이 많이 쓰는 언어들을 바탕으로 연구가 되기 때문.
-
유명한 한국어 NLU 데이터 셋이 전형적으로 QA나 감정 분석은 포함은 되어있는데 NLI나 STS는 아니다. -> 한국어로 된 공개 NLI나 STS 벤치마크 데이터셋이 없어서 이런 핵심과제에 적합한 한국어 NLU 모델 구축에 대한 관심이 부족했다고 생각한다.
-
이에 동기를 얻어 KorNLI와 KorSTS를 만들었으며, 앞서 이야기했듯 훈련 세트는 기계번역, develop set과 test set은 수동으로 번역했다.
2. Background
2.1 NLI and the {S, M, X} NLI Datasets
-
NLI과제에서, 시스템은 한 쌍의 문장, 전제와 가설을 받고 그 관계를 얽힘(entailment), 모순(contradiction), 중립(neutral) 중 하나로 분류.
-
다양한 데이터 셋이 공개
-
Bowman과 연구진은 이미지 캡션에 기반한 570K 개의 영어 문장 쌍으로 구성된 Stanford NLI(SNLI)
-
Williams와 연구진은 10개의 장르에서 455K 개의 영어 문장 쌍으로 구성된 Multi-Genre NLI(MNLI)
-
Conneau와 연구진은 MNLI 말뭉치의 development 데이터와 test 데이터를 15개의 언어로 확장한 Cross-lingual NLI(XNLI). 이 15개의 언어 중에 한국어는 없다.
-
2.2 STS and STS-B Dataset
STS
-
두 문장 사이의 의미적 유사성과 그래프를 평가하는 과제. 유사성 점수는 0부터 5까지 매기며 숫자가 클 수록 의미가 가깝다고 본다.
-
모델이 의미상 두 문장의 친밀도를 얼마나 잘 잡아내는지 또는 문장의 의미적 표현을 얼마나 잘 구현하는지 평가하는데 일반적으로 사용된다.
STS-B
-
2012년에서 2017년까지 SemEVal의 컨텍스트에서 구성된 STS 과제에서 선택한 8,628개의 영어 문장 쌍으로 구성
-
입력 문장의 도메인은 이미지 캡션, 뉴스 헤드라인, 유저 포럼.
3. Data
3.1 Data construction
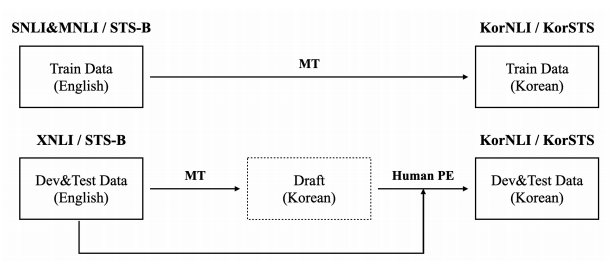
-
한국어 이해를 위한 데이터셋인 KorNLI와 KorSTS를 어떻게 개발했는지에 대한 설명
-
KorNLI 데이터셋은 SNLI, MNLI, XNLI에서 파생되었으며, KorSTS 데이터 셋은 STS-B 데이터셋을 기반으로 만들어짐.
- 두 개의 새로운 데이터셋에 동일하게 적용되는 전체 구축 프로세스는 figure 1에 설명되어 있다.
-
먼저 SNLI, MNLI, STS-B 데이터셋의 훈련 셋과 XNLI, STS-B의 development와 test 셋을 Kakao로부터 내부 기계 번역 엔진을 사용해 한국어로 번역한다.
-
그 다음, 개발과 테스트셋의 번역 결과를 평가의 퀄리티를 보장하기 위해 전문 번역가에게 사후 평가시켰다.
-
이런 다단계의 번역 전략 목표는 번역가의 일을 빠르게 처리하는 것 뿐만 아니라, 훈련과 평가 데이터셋 간의 번역 일관성을 유지하는데도 도움이 된다.
-
사람이 직접 번역한 것에 대한 퀄리티를 보증하기 위해, 기계 번역의 결과물을 반으로 나누고, 두 명의 인간 전문가가 그것들을 편집하도록 한다.
-
사후 편집 절차가 단순히 교정을 의미하는 것이 아니라는 점에 주목할 필요가 있다. 오히려 이전의 기계 번역 결과를 바탕으로한 사람이 직접한 번역을 말하며, 이것은 초안이 된다. 이 작업이 다 되면, 번역가 모두에가 각각 크로스 체크를 요청한다.
- 마지막으로 마이크로소프트 워드로 스펠링과 문법을 체크하며, 수동으로 오류를 수정한다.
3.2 KorNLI
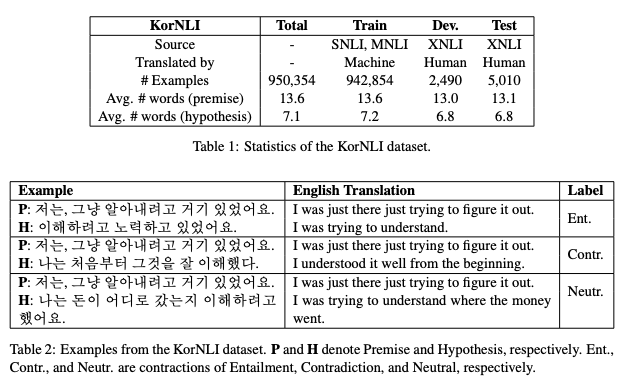
-
표 1은 KorNLI 데이터셋의 통계를 보여준다. 942,854개의 훈련 예제를 자동으로 번역하고, 7,500개의 평가(개발과 테스트) 예제를 수동으로 번역했다. 이 전제는 Connau와 연구진들이 보고한 가설보다 약 두 배 정도 많다.
-
몇 가지 예제를 표 2에 작성됨.
3.3 KorSTS
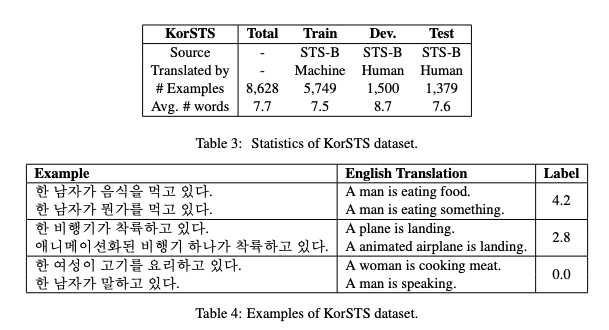
표 3에 제공한 것처럼, KorSTS 데이터 셋은 5,749개의 훈련 예제들을 기계 번역했으며, 2,879개의 평가 예제들을 수동으로 번역했다. 평균적으로 한 문장은 7.5개의 단어를 가진다. 예시는 표 4에서 보여준다.
4. Baselines
새롭게 만들어진 벤치마크 데이터 셋을 사용해 한국어 NLI와 STS과제의 베이스라인을 제공한다. -> 두 작업 모두 한 쌍의 문장을 입력으로 받기 때문에, 모델이 문장을 공동으로 인코딩(“cross-encoding”) 또는 별도로 인코딩(“bi-encoding”)하는지에 따라 두 가지 접근법이 있기 때문.
4.1 Cross-Encoding Approaches
-
BERT에서 묘사된 것과 BERT의 많은 변형들로부터 NLU 과제에 대한 사실상의 표준 접근방식은 대규모 언어 모델을 사전 교육하고 각 과제에 대해 미세 조정하는 것.
-
cross-encoding 접근법에서, 사전 훈련된 언어 모델은 미세 조정을 위해 각 문장 쌍을 하나의 입력으로 받는다.
-
이런 cross-encoding 모델은 전형적으로 입력된 각 문장을 따로 인코딩하는 bi-encoding 모델을 넘어서 state-of-the-art 퍼포먼스를 달성한다.
-
KorNLI와 KorSTS 모두, 우리는 두 개의 사전 훈련된 모델을 고려.
-
한국어 RoBERTa base버전과 large버전 모두 사전 훈련하고, 내부적으로 한국어 코퍼스들으로 수집한다. 이게 65GB정도 됨.
-
SentencePiece를 사용해 32K개의 토큰 byte pair encoding(BPE) dictionary를 구축한다.
-
모델 훈련은 32개의 V100 GPU를 사용해 base모델은 25일, 64개의 V100 GPU를 사용해 large모델은 20일동안 fairseq를 통해 진행했다.
-
또한 공개적으로 사용가능한 cross-lingual 언어 모델인 XLM-R을 사용하며, 한국어가 포함된 100개의 언어로 이루어진 Common Crawl 말뭉치들을 가지고 훈련시켰다. XLM-R의 base와 large모델의 구조는 단어사전 크기가 훨씬 크며(250K), 임베딩 및 출력 레이어를 훨씬 크게 만드는 것 빼고는 RoBERTa와 동일하다.
-
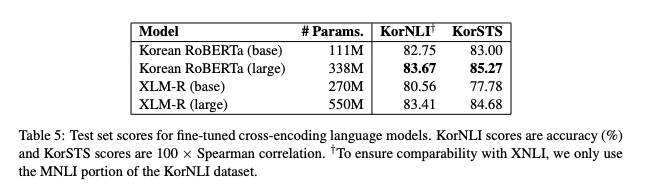
표 5에서, KorNLI(정확도)와 KorSTS(스피어맨 상관계수)의 테스트셋 점수를 보고한다. KorNLI에서, XNLI와의 비교 가능성을 보장하기 위해 KorNLI 데이터 세트의 MNLI 부분만 교육한다. 전반적으로 한국어 RoBERTa 모델이 크기가 작음에도 불구하고, 각각의 크기(base, large)에서 XLM-R 모델을 능가한다.
-
각 모델에서, large 모델은 base를 능가하며, Liu와 연구진들이 발표한 결과와 일치한다. 한국어 RoBERTa의 large 모델은 시험된 모든 모델들 중에서 KorNLI(83.67)와 KorSTS(85.75)로 가장 좋은 결과를 보여준다.
-
4.2 Bi-Encoding Approaches
-
bi-encoding 접근법은 큰 문장의 집합들 사이의 쌍방향 유사성을 계산하는 것이 cross-encoding을 활용한 계산비용이 비싼 의미론적 검색과 같은 어플리케이션에서 실질적인 중요성을 갖는다.
-
먼저 사전 교육을 받은 언어 모델을 사용하지 않는 두 가지 기준선, 즉 한국어 빠른 텍스트와 다국어 범용 문장 인코더(M-USE)를 제공한다. 한국어 fastText는 Common Crawl의 한국어 텍스트를 훈련한 워드 임베딩 모델이다. 문장 임베딩 제작을 위해, 각 문장에 대한 fastText 단어 임베딩의 평균을 취한다.
-
M-USE는 한국어를 포함한 16개 언어에 걸쳐 NLI, 질의응답, 번역 순위에 대해 훈련된 CNN 기반의 문장 인코더 모델. 한국어 fastText와 M-USE 모두 비지도 STS 예측을 하기 위해 두 입력 문장 임베딩간 코사인 유사도를 계산한다.
-
사전훈련된 언어 모델은 NLI 및/또는 STS 의 Siamese 네트워크 구조로 BERT와 유사한 모델을 미세 조정해야 하는 SentenceBERT의 접근에 따른 bi-encoding 모델로 사용될 수 있다.
-
한국어 RoBERTa(“Korean SRoBERTa”)와 XLM-R(“SXLM-R”) 모두 SentenceBERT 접근법을 사용했다. MEAN pooling 전략을 사용. 즉 문장 벡터를 모든 상황별 단어 벡터의 평균으로 계산한다.
-
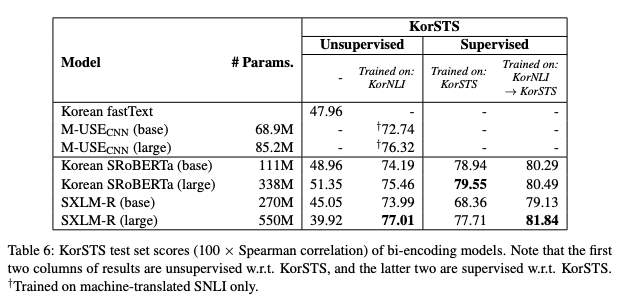
표 6에서 bi-encoding모델의 KorSTS 테스트셋의 점수(스피어만 상관계수)를 제공. 모델이 KorNLI 및/또는 KorSTS 에 대해 추가적인 학습을 했는지 여부에 따라서 각 결과를 분류함.
5. Conclusion
- 한국어 NLU를 위한 새로운 데이터 셋을 소개.
- 이 데이터셋을 사용해 cross-encoding 및 bi-encoding 방식을 모두 사용하여 한국어 NLI와 STS의 베이스라인을 설정
- 이걸로 한국의 NLU 시스템 개선에 대한 향후 연구가 활발히 이루어지길 바란다.