![[논문 뽀개기] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://www.effettoundici.it/wp-content/uploads/2020/01/22d0859e46b8edf659638449e258a224_Bert-google-algorithmus2-1024-683-c.png)
보면 볼수록 귀엽단 말이지
읽기 전에
이 글은 NLP 분야에 큰 발전을 가져온 BERT에 대한 논문을 한글로 번역한 글이다. 중간중간 오역이 있을 수 있다.
BERT의 T가 Transformer인 만큼, BERT는 Transformer의 구조와 거의 흡사하다. 대신, 기존 Transformer의 Encoder만을 활용하며, Masked LM을 활용한 빈 칸 맞추기, Next sentence prediction 등 사전 훈련을 통해 정확성을 높이 올렸다.
또한 이 논문에서는 Fine-tuning 기반 위주로 작성되었으나 후술하는 Feature-based에서도 좋은 결과를 보여주며, 최소한의 파라미터 수정만으로 대부분의 NLP 과제에서 좋은 성적을 내는 모습을 보여주었다.
Abstract
우리는 트랜스포머의 양방향 인코더 표현(Bidirectional Encoder Representations from Transformers)을 의미하는 BERT라는 새로운 언어 표현 모델을 소개한다. 최근 언어 표현 모델들과 달리, BERT는 모든 레이어에 양방향 문맥에서 공동으로 조절함으로써 라벨이 없는 텍스트로부터 깊은 양방향 표현들을 사전 훈련하도록 디자인되었다. 이에 대한 결과로, 사전 훈련된 BERT 모델은 작업별 구조 수정을 크게 할 필요 없이(without substantial task-spcific architecture modification) 질문 답변과 언어 추론과 같은 넓은 분야의 작업에서 state-of-the-art 모델을 만들기 위해 그냥 하나의 출력 레이어만 추가만 해도 파인튜닝될 수 있다. BERT는 컨셉적으로 간단하며 실질적으로(empirically) 파워풀하다. 이것은 GLUE 점수를 80.5%(7.7% 절대적 향상), MultiNLI 정확도를 86.7%, SQuAD v1.1 질문 답변 테스트 F1을 93.2(1.5 point 절대적 향상) 그리고 SQuAD v2.0 테스트 F1에서 83.1(5.1 point 절대적 향상) 등을 포함해 열 한개의 자연어 처리 작업에서 새로운 state-of-the-art 결과를 얻는다.
1. Introduction
언어 모델을 사전 훈련하는 것은 많은 자연어 처리 작업 향상에 효과적이라고 알려졌다. 여기에는 문장 간의 관계를 전체적으로 분석하여 예측하는 것을 목표로 하는 자연어 추론 및 의역(paraphrasing)과 같은 문장 수준의 과제와, 토큰 수준에서 미세한 산출물을 산출하기 위해 모델이 요구되는 명명된 실체 인식 및 질문 답변과 같은 토큰 수준의 과제가 포함된다.
다운 스트림 과제를 위해 사전 훈련된 언어 표현들을 적용하는 것에는 두 가지 전략이 존재한다. feature-based와 미세조정(fine-tuning)이다. ELMo와 같은 feature-based 접근 방식은 사전 훈련된 표현들을 추가 기능으로 포함하는 작업별 구조를 사용한다. 생성적 사전 훈련된 트랜스포머(Generative Pre-trained Transformer, GPT)와 같은 미세 조정 접근 방식은 최소한의 작업별 파라미터를 도입하고, 모든 사전 훈련된 파라미터를 간단하게 미세조정함으로써 다운스트림 과제에 대해 훈련한다. 이 두가지 접근 방식은 사전 훈련동안 같은 목적 함수(objective function)을 공유하며, 여기서 일반적인 언어 표현을 학습하기 위해 단방향 언어 학습 모델을 사용한다. 우리는 현재 기술들은 특히 미세 조정 접근 방식에 대해 사전 훈련된 표현들의 힘을 제한한다고 주장한다. 가장 큰 한계는 표준 언어 모델들이 단방향이며 이것은 사전 훈련 동안 사용될 수 있는 구조의 선택에 한계가 있다. 예를 들어 OpenAI GPT에서, 작가들은 모든 토큰이 트랜스포머의 셀프 어텐션 레이어에서 이전 토큰에만 참조를 확인할 수 있는 ‘왼쪽에서 오른쪽으로’ 구조를 사용한다. 이러한 제한은 문장 수준의 업무에 최적이 아니며, 질문 답변과 같은 토큰 수준의 작업을 위한 미세 조정 기반의 접근 방법을 적용할 때 매우 좋지 않을 수 있는데, 이 때 양방향에서 문맥을 통합하는 것이 중요하다.
이 논문에서, BERT: Bidirectional Encoder Representations from Transformers를 제안함으로써 미세 조정 기반 접근 방법을 향상시킨다. BERT는 Cloze 업무에 의해 영감을 받은 사전 훈련을 목적으로 하는 ‘마스킹된 언어 모델(masked language model, MLM)’을 사용함으로 이전에 언급된 단방향성 제약을 완화시킨다. 마스킹된 언어 모델은 무작위로 입력으로부터의 토큰 일부를 마스킹하고 목적은 오직 그 맥락 안에서 마스킹된 단어 기반으로 원래의 단어 ID를 예측하는 것이다. ‘왼쪽에서 오른쪽으로’의 언어 모델 사전 훈련과 달리, MLM의 목적은 표현이 왼쪽과 오른쪽 맥락을 융합할 수 있게 하며, 이것은 우리가 깊은 양방향 트랜스포머를 사전 훈련할 수 있게 한다. 마스킹된 언어 모델 외에도 우리는 사전 훈련된 텍스트 쌍 표현을 공동으로 하는 “다음 문장 예측” 작업 또한 사용한다. 이 논문의 기여는 다음과 같다.
-
우리는 언어 표현을 위한 양방향 사전 훈련의 중요성을 증명한다. 사전 훈련을 위해 단방향 언어 모델을 사용한 Radford et al. (Improving language understanding with unsupervised learning. 2018)과 달리 BERT는 깊은 양방향 표현을 사전 훈련이 가능하도록 마스킹된 언어 모델을 사용한다. 이것은 또한 독립적으로 훈련된 ‘왼쪽에서부터 오른쪽으로’와 ‘오른쪽에서부터 왼쪽으로’ 언어 모델의 얕은 결합을 사용한 Peters et al. (Deep contextualized word representations. 2018a)와 대조적이다.
-
우리는 사전 훈련된 표현이 많은 고도로 설계된(heavily-engineered) 작업별 아키텍처의 필요성이 줄어든다는 것을 보여준다. BERT는 문장 수준 및 토큰 수준 작업으로 이루어진 대규모 집합에서 state-of-the-art 성능을 달성해 많은 작업별 구조를 능가하는 최초의 미세 조정 기반 표현 모델이다.
-
BERT는 11개의 NLP 작업에서 최첨단으로 발전시켰다.
2. Related Work
사전 훈련하는 일반적인 언어 표현에는 긴 역사가 있으며, 우리는 간단하게 가장 많이 쓰이는 접근법들을 이 섹션에서 리뷰한다.
2.1 Unsupervised Feature-based Approaches(비지도 특징 기반 접근 방식)
넓게 적용 가능한 단어의 표현을 배우는 것은 비신경, 신경 방법들을 포함해 수 십년 동안 활발한 영역(active area of research)이었다. 사전 훈련된 단어 임베딩은 현대 NLP 시스템의 필수적인 부분으로, 밑바닥부터 훈련된 임베딩을 넘어서는 효과적인 향상을 제공한다. 워드 임베딩 벡터를 사전 훈련하기 위해, ‘왼쪽에서부터 오른쪽으로’ 언어 모델링 objetive가 사용되어졌으며, 좌우 맥락에서 잘못된 단어로부터 올바르게 구별하기 위한 objective도 사용되어 왔다. 이러한 접근법들은 문장 임베딩 또는 단락 인베딩과 같이 보다 세밀한 세분화로 일반화되어졌다. 문장 표현을 학습하기 위해, 이전의 작업들은 다음 문장의 후보들의 순서를 매기거나, 이전 문장의 주어진 표현으로 ‘왼쪽에서 오른쪽으로’ 다음 문장 단어를 생성하는 것 또는 오토 인코더로부터 파생된 objective 노이즈 삭제 등을 사용했다.(To train sentence representations, prior work has used objectives to rank candidate next sentences (Jernite et al., 2017; Logeswaran and Lee, 2018), left-to-right generation of next sentence words given a representation of the previous sentence (Kiros et al., 2015), or denoising autoencoder derived objectives (Hill et al., 2016).).
ELMo와 그 전임자는 다른 차원을 따라 전통적인 단어 임베딩 연구를 일반화한다. 그들은 ‘왼쪽에서부터 오른쪽으로’ 와 ‘오른쪽에서부터 왼쪽으로’언어 모델로부터 문맥에 민감한 기능들을 추출한다. 각 토큰의 문맥상의 표현은 ‘왼쪽에서부터 오른쪽으로’와 ‘오른쪽에서부터 왼쪽으로’ 표현의 결합이다. 상황별 단어 임베딩들을 기존의 작업별 구조와 통합할 때, ELMo는 질문 답변, 감정 분석, 명명된 개체 인식을 포함한 몇 가지 주요 NLP 벤치마크에 대해 최첨단으로 발전시켰다. Melamud와 연구진 (context2vec: Learning generic context embedding with bidirectional LSTM. 2016)들은 LSTM을 사용해 왼쪽과 오른쪽 문맥 모두로부터 단어를 예측하기 위한 작업을 통해 문맥적 표현을 학습하는 것을 제안했다. ELMo와 유사하게 이들의 모델은 특징 기반이고 깊지 않은 양방향이다. Fedus와 연구진들은 빈칸 채우기 작업을 텍스트 생성 모델의 견고성을 향상시키는 데 사용할 수 있음을 보여준다
2.2 Unsupervised Fine-tuning Approaches(비지도 미세조정 접근 방식)
특징 기반 접근 방식들과 마찬가지로, 이 방향에서 첫 번째 작업은 레이블이 없는 텍스트로부터 사전 훈련된 단어 임베딩 파라미터만 사용한다. 좀 더 최근에는, 상황별 토큰 표현을 생성하는 문장 혹은 문서 인코더가 레이블이 없는 텍스트에서 사전 훈련되어 지도되는 다운스트림 과제에 맞게 미세조정되었다. 이러한 접근 방식의 장점은 밑바닥에서부터 학습할 파라미터가 거의 없다는 것이다. 적어도 이 장점때문에 부분적으로 OpenAI GPT는 이전에 GLUE 벤치마크로부터 많은 문장 레벨 작업에 state-of-the-art 결과를 달성했다. ‘왼쪽에서부터 오른쪽으로’ 모델링과 오토 인코더 Objective는 다음과 같은 모델(Universal language model fine-tuning for text classification, Improving language understanding with unsupervised learning, Semi-supervised sequence learning.)에서 사전 훈련하기 위해 사용된다.
2.3 Transfer Learning from Supervised Data(지도 데이터로부터 전이 학습)
또한 자연어 추론과 기계 번역과 같은 대규모 데이터 셋을 사용하여 지도 작업으로부터 효과적인 전이를 보여주는 작업도 있었다. 컴퓨터 비전 연구는 또한 ImageNet으로 사전 훈련된 모델을 미세 조정하기 위한 효과적인 레시피인 대규모 사전 훈련된 모델에서 전이 학습의 중요성을 입증했다.
3. BERT
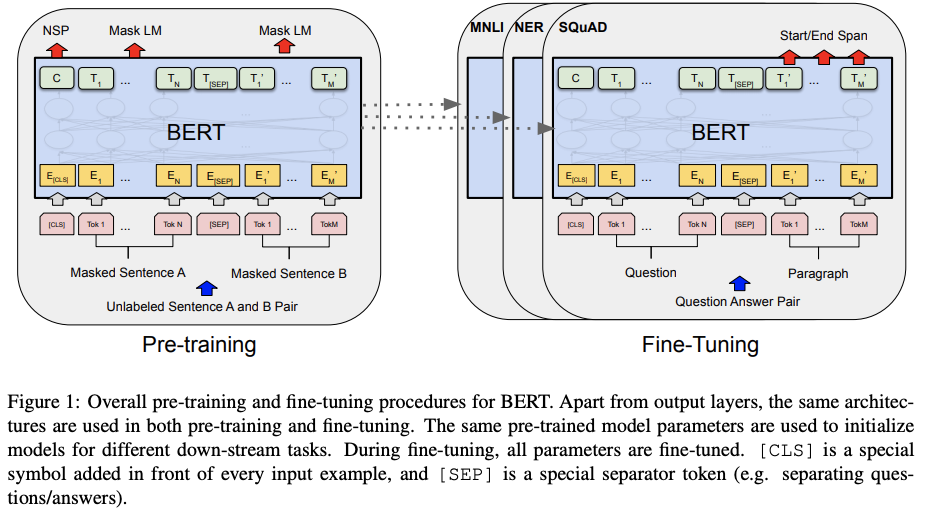
우리는 BERT와 세부적인 요소들을 이 섹션에서 소개한다. 우리의 프레임워크에는 사전 훈련과 미세 조정 두 단계가 있다. 사전 훈련동안, 모델은 다른 사전 훈련하는 작업에 걸쳐 라벨이 붙지 않은 데이터에 대해 훈련된다. 미세 조정을 위해, BERT 모델은 먼저 사전 훈련된 파라미터로 초기화되고, 모든 파라미터는 다운스트림 과제에서 라벨이 붙은 데이터를 사용해 미세조정 된다. 각 다운스트림 과제들은 사전 훈련된 동일한 매개변수로 초기화되더라도 별도로 미세 조정된 모델이 있다. Figure 1에 있는 질문 답변 예제는 이 섹션의 실행 예제로서 역할을 할 것이다. BERT의 구별된 특징은 다양한 작업에 걸친 통일된(unified) 구조라는 것이다. 사전 훈련된 구조와 마지막 다운 스트림 구조 사이의 최소한의 차이만 있다.
Model Architecture BERT의 모델 구조는 Vaswani et al.(Attention is all you need.)에 기술된 원래 구현에 기초한 다중 레이어 양방향 트랜스포머 인코더로, tensor2tensor 라이브러리에 공개된다. 왜냐하면 트랜스포머의 사용이 일반화되었고 우리의 구현이 원문과 거의 동일하기 때문에, 모델 구조에 대한 철저하게 배경 설명은 생략하고 독자들에게 “The Annotated Transformer”와 같은 훌륭한 가이드를 참조할 것이다. 이 작업에서, 우리는 레이어의 개수(트랜스포머 블럭 등)를 $L$, 은닉의 크기는 $H$, 셀프 어텐션 헤드의 수는 $A$ 로 나타낸다. 우리는 주로 $\mathbf{BERT_{BASE}}$ (L=12, H=768, A=12, Total Parameters=110M)과 $\mathbf{BERT_{LARGE}}$ (L=24, H=1024, A=16, Total Parameters=340M) 두 모델 사이즈에 대한 결과를 보고한다.
$\mathbf{BERT_{BASE}}$ 는 같은 모델 사이즈인 OpenAI GPT와 비교를 목적으로 선택된다. 그러나 결정적으로 BERT 트랜스포머는 양방향 셀프 어텐션을 사용하는 반면, GPT 트랜스포머는 모든 토큰이 왼쪽 문맥만 처리할 수 있게만 하는(강요받는) 셀프 어텐션을 사용한다.

Input/Output Representations 다운스트림 과제의 다양성을 다룰 수 있는 BERT를 만들기 위해 우리의 입력 표현은 단일 문장과 문장의 쌍(예: <질문, 답변>)을 하나의 토큰 순서로 명확하게 나타낼 수 있다. 이 작업 내내, ‘문장(Senetence)’는 실제 언어의 문장 대신에 인접한 텍스트의 임위 범위가 될 수 있다. ‘시퀀스(Sequence)’는 BERT에 대한 입력 토큰 시퀀스를 말하며 하나의 문장 또는 두 개의 문장을 함께 패킹한 것일 수 있다. 우리는 30,000개의 토큰 단어를 사용하는 WordPiece 임베딩을 사용한다. 모든 문장의 첫 번째 토큰은 항상 특별한 분류토큰($\mathsf{[CLS]}$)이다. 이 토큰에 해당하는 마지막 은닉 상태(hidden state)는 분류 작업을 위해 총 시퀀스 표현으로 사용된다. 문장의 쌍은 하나의 시퀀스로 함께 묶인다. 우리는 두 가지 방법으로 문장을 구별한다. 먼저, 우리는 특별한 토큰 ($\mathsf{[SEP]}$)과 함께 문장들을 분리한다. 두 번째로 우리는 모든 토큰에 이것이 문장 A인지 B인지 표시하는 학습된 임베딩을 추가한다. Figure 1에서 보여주듯이, 우리는 임베딩을 $E$, 특별한 $\mathsf{[CLS]}$ 토큰의 마지막 은닉 벡터를 $C \in \mathbb{R}^{H}$, $i^{th}$ 입력 토큰의 마지막 은닉 벡터를 $T_i \in \mathbb{R}^{H}$로 나타낸다.
주어진 토큰의 경우, 이것의 입력 표현은 해당 토큰, 세그먼트 및 위치 임베딩을 합쳐서 구성된다. 이 구성의 시각화는 Figure 2에서 볼 수 있다.
3.1 Pre-training BERT
Peters et al. (Deep contextualized word representations. 2018a)와 달리, 우리는 BERT를 사전 훈련하기 위해 전통적인 ‘왼쪽에서부터 오른쪽으로’나 ‘오른쪽에서부터 왼쪽으로’ 언어 모델을 사용하지 않았다. 대신에 우리는 BERT를 이번 섹션에서 설명된 두 가지 비지도 작업을 사용해 사전 훈련했다. 이번 단계는 Figure 1의 왼쪽 부분에 표현되어 있다.
Task #1: Masked LM 직관적으로, 깊은 양방향 모델이 다른 ‘왼쪽에서부터 오른쪽으로’ 모델이나 ‘왼쪽에서부터 오른쪽으로’ 모델과 ‘오른쪽에서부터 왼쪽으로’ 모델들의 얕은 결합보다 절대적으로 더 좋다는 것을 믿는 것이 합리적이다. 불행하게도, 일반적인 조건부 언어 모델들은 양방향 조절은 각 단어가 간접적으로 ‘자체 보기(see itself)’를 허용하며 모델은 다중 레이어 문맥에서 대상 단어를 좋지 않은 예측을 할 수 있기 때문에 ‘왼쪽에서부터 오른쪽으로’나 ‘오른쪽에서부터 왼쪽으로’만 훈련할 수 있다.
깊은 양방향 표현을 훈련시키기 위해, 우리는 무작위로 입력 토큰의 몇 퍼센트를 간단하게 마스킹하고, 그 다음 마스킹된 토큰들을 예측한다. 문헌에서는 흔히 클로즈(Cloze) 작업이라고 하지만, 이 절차를 ‘마스크 처리된 LM(MLM)’이라고 부른다. 이 경우에, 마스크 토큰에 해당하는 마지막 은닉 벡터는 표준 LM에서와 같이 어휘를 통해 출력 소프트맥스로 공급된다. 우리의 모든 실험에서, 우리는 무작위로 모든 WordPiece 토큰의 15%를 무작위로 각 시퀀스에서 마스킹한다. denoising auto-encoders와 대조적으로, 우리는 전체 입력 재구성 대신 마스킹된 데이터만 예측한다.
비록 이것은 양방향 사전 훈련된 모델을 얻을 수 있지만, 미세 조정 중에 [MASK] 토큰이 나타나지 않기 때문에, 사전 훈련과 미세 조정 사이에 불일치를 만들어내는 단점이 있다. 이것을 완화시키기 위해, 우리는 항상 “마스킹된(masked)” 단어를 실제 [MASK] 토큰으로 교체하지 않는다. 훈련 데이터 생성기는 예측을 위해 무작위로 토큰 포지션의 15%를 선택한다. 만약 i 번째 토큰이 선택된다면, 우리는 i 번째 토큰을 (1) 80%는 [MASK] 토큰으로 교체하거나 (2) 10%는 임의 토큰으로 교체, (3) 10%는 변경되지 않은 i 번째 토큰을 사용한다. 그 다음 $T_i$는 크로스 엔트로피 손실과 함께 원래의 토큰을 예측하기 위해 사용될 것이다. 우리는 부록에 있는 이 절차의 변화를 비교한다.
Task #2: Next Sentence Prediction (NSP) 질문 답변(QA), 자연어 추론(NLI)와 같이 많이 중요한 다운스트림 과제는 언어 모델에 의해 직접적으로 포착되지 않는 두 문장 간의 관계 이해를 기반으로 한다. 모델이 문장 관계를 이해하는 것을 훈련시키기 위해, 우리는 어떤 하나의 언어를 사용하는 말뭉치로부터 생성될 수 있는 다음 문장 예측 과제를 2진화(binarized)하기 위해 사전 훈련한다. 구체적으로 각 사전 훈련의 예제에 대해 문장 A, B를 선택할 때 B의 50%는 A 다음에 오는 실제 다음 문장(IsNext 로 라벨링됨), 50%는 말뭉치의 임시 문장(NotNext로 라벨링됨)이다. Figure 1에서 보여주듯이, C는 다음 문장 예측(NSP)에서 사용된다. 단순함에도 불구하고 우리는 섹션 5.1에서 이 과제를 위한 사전 훈련이 QA(질문 답변)와 NLI(자연어 추론) 모두에 매우 유익하다는 것을 증명한다. NSP 과제는 Jernite et al.(Discourse-based objectives for fast unsupervised sentence representation learning) 및 Logeswaran and Lee(An efficient framework for learning sentence representations.) 에서 사용된 표현 학습 목표와 밀접하게 관련이 있다. 그러나 이전의 연구에서, 문장 임베딩만이 다운스트림 과제로 전이되며, 여기서 BERT는 엔드 과제 모델 파라미터를 초기화하기 위해 모든 매개 변수를 전이한다.
Pre-training data 사전 훈련 절차는 언어 모델 사전 훈련에 관한 기존의 문헌을 대체로 따른다. 사전 훈련 corpus를 위해 우리는 BooksCorpus(800M개의 단어), 영어 위키피디아(2,500M개의 단어)를 사용한다. 위키피디아의 경우, 우리는 텍스트 구절만 추출하고 목록, 표, 머리글은 무시한다. 긴 연속적인 시퀀스를 추출하려면 Billion Word Benchmark와 같이 이것저것 섞인(shuffled) 문장 레벨 코퍼스가 아닌 문서 레벨 코퍼스를 사용하는 것이 중요하다.
3.2 Fine-tuning BERT
트랜스포머의 셀프 어텐션 메커니즘은 BERT가 적절한 입력과 출력을 교환함으로써 단일 텍스트 혹은 텍스트 쌍을 포함하든간에 많은 다운스트림 작업을 모델링할 수 있도록 해주기 때문에 미세조정은 아주 간단하다. 텍스트 쌍을 포함하는 어플리케이션의 경우, 공통 패턴은 Parikh et al.(A decomposable attention model for natural language inference.)등 과 같은 양방향 크로스 어텐션을 적용하기 전에 텍스트 쌍을 독립적으로 인코딩하는 것이다; Seo et al.(Bidirectional attention flow for machine comprehension.). 대신에 BERT는 셀프 어텐션으로 연결된 텍스트 쌍을 인코딩하는 것은 두 문장 사이의 양방향 교차 주의를 효과적으로 포함하므로 이 두 단계를 통합하기 위해 셀프 어텐션 메커니즘을 사용한다.
각 작업마다 우리는 작업별 입력과 출력을 BERT에 연결하고 모든 파라미터를 엔드 투 엔드로 미세 조정한다. 입력에서 사전 훈련에서 나온 문장 A와 B는 (1) 패러프레이싱(다른 말로 바꾸어 표현하는 것)의 문장 쌍, (2) 수반되는 가설-전제, (3) 문제의 질문-통과 쌍 (4) 텍스트 분류 또는 순서 태깅의 변질된 텍스트-$\phi$ 쌍과 유사하다. 출력에서 토큰 표현은 시퀀스 태그 지정이나 질문 응답과 같이 토큰 레벨의 작업을 위한 출력 계층으로 공급되며, [CLS] 표현은 수반이나 감성 분석과 같은 분류를 위한 출력계층으로 공급된다.
사전 훈련과 비교해서 미세 조정은 상대적으로 비싸지 않다. 논문의 모든 결과들은 정확히 동일한 사전 훈련된 모델에서 시작하여 단일 클라우드 TPU에서 최대 한 시간 또는 GPU에서 몇 시간 내에 복제될 수 있다. 우리는 섹션 4의 해당 하위 섹션에 업무별 세부사항들을 기술한다. 더 많은 세부사항들은 부록 A.5에서 찾을 수 있다.
4. Experiments
각 과제별 테스트 결과를 작성한 부분이므로 패스.
5. Ablation Studies
c.f.) Ablation study 란?
모델이나 알고리즘의 기능(feature)들을 하나씩 제거해보면서 이 기능이 전체 성능에 얼마나 영향을 미치는 지 확인해보는 것이다.
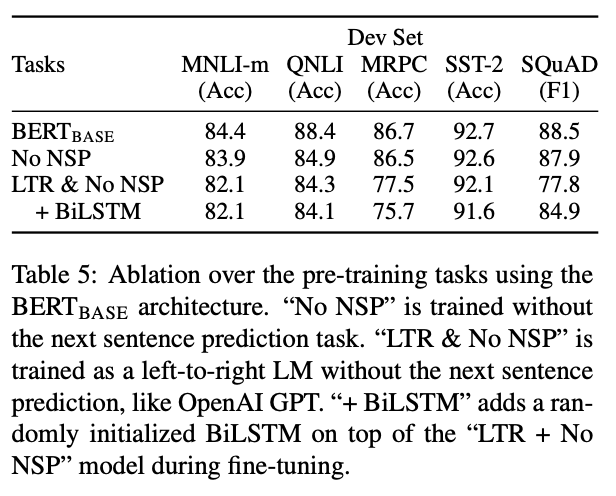
이 섹션에서 우리는 상대적인 중요성을 더 잘 이해하기 위해 BERT의 여러 면에 걸쳐서 ablation 실험을 수행한다. 추가적인 ablation 연구는 부록 C에서 찾을 수 있다.
5.1 Effect of Pre-Training Tasks
정확히 같은 사전 훈련 데이터, 미세 조정 scheme, $\mathbf{BERT}_{\text{BASE}}$의 하이퍼 마라미터를 사용해 두 가지의 사전 훈련 목표에 의한 평가로 BERT의 깊은 양방향성의 중요성을 입증한다.
No NSP: “다음 문장 예측(NSP)” 과제를 하지 않은, “마스킹된 LM(MLM)”을 사용해 훈련된 양방향 모델
LTR & No NSP: MLM 대신 일반적인 “왼쪽에서 오른쪽으로 언어 모델(Left-to-Right(LTR) LM)”을 사용해 훈련된 오로지 왼쪽에서 오른쪽으로 이어지는 문맥을 가진 모델(left-context-only-model)이다. 왼쪽에서만 (left-only) 이어지도록 하는 제약은 미세 조정시에도 적용되는데, 이를 제거하면 사전 훈련/미세 조정 불일치가 발생해 다운스트림 과제에서 좋지 못한 성능을 보여주기 때문이다. 또한 NSP 과제 없이 사전 훈련 되었다. 이것은 직접적으로 OpenAI GPT와 비교하지만, 우리가 설정한 대용량 데이터셋, 입력 표현, 미세조정 scheme을 사용한다.
우리는 먼저 NSP 과제에 대한 영향력을 먼저 검토한다. 표 5에서, 우리는 NSP를 제거하는 것이 QNLI, MNLI와 SQuAD 1.1에서 퍼포먼스를 상당히 하락시킨다는 것을 보여준다. 다음, 우리는 “No NSP”와 “LTR & No NSP”를 비교하면서 양방향 표현을 훈련하는 것의 영향력을 평가한다. LTR 모델의 퍼포먼스는 MLM 모델보다 MRPC와 SQuAD에 큰 영향을 미치는(large drops) 모든 과제에 대해서 좋지 않다.
SQuAD에 대해 LTR모델은 토큰 레벨 은닉 상태가 우측 문맥이 없기 때문에 토큰 예측을 잘 못할 것이다는 것은 직관적으로 명확하다. LTR 시스템을 강화하는 시도에 좋은 믿음(faith)을 만들기 위해서 우리는 무작위로 초기화된 BiLSTM을 맨 위에 추가한다. 이건 SQuAD에서 효과적으로 결과를 향상시켰지만, 결과는 사전 훈련된 양방향 모델에 비해 여전히 꽤 나쁘다. BiLSTM이 GLUE 작업에서 성능을 해친다.
우리는 또한 ELMo가 하는 것처럼 별도의 LTR 및 RTL 모델을 훈련하고 각 토큰을 두 모델의 연결로 나타내는 것이 가능할 것이라고 인정한다. 그러나
- 두 번 계산하기 때문에 단일 양방향 모델에 비해 두 배로 계산비용이 비싸다.
- RTL 모델은 질문에 대한 답변을 조절할 수 없기 때문에, QA(Question and Answer)와 같은 작업에 대해서 직관적이지가 않다.
- 깊은 양방향 모델은 모든 레이어에서 왼쪽과 오른쪽 문맥 모두 사용할 수 있기 때문에, 이 모델보다는 성능이 낮을 수 밖에 없다.
5.2 Effect of Model Size
이 섹션에서, 우리는 모델 크기가 미세 조정 작업 정확도에 미치는 영향을 탐구한다. 우리는 많은 BERT 모델을 이전에 적었던 것처럼 같은 파라미터와 훈련 절차를 사용한 반면, 레이어의 수, 은닉 상태 개수, 어텐션 헤드 개수를 다르게 훈련했다.
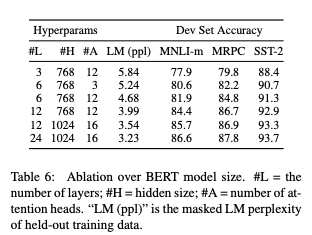
선택한 GLUE 작업들의 결과는 표 6에서 보여준다. 이 표에서, 우리는 미세 조정의 무작위 재시작을 5회 실시했을 때 평균 DevSet 정확도를 보고한다. 우리는 더 큰 모델이 3,600개의 라벨이 붙은 훈련 샘플만 가지고 있고, 사전 훈련 작업과 실질적으로 다른 MRPC에 대해서도 4개의 데이터셋 모두에서 정확도를 엄격하게(strict, 큰 차이가 났다는 듯) 향상시킨다는 것을 알 수 있다. 또한 우리가 현존하는 문헌에 비해 이미 상당히 큰 모델들 위애 그러한 유의미한 개선을 달성할 수 있다는 것은 어쩌면 놀라운 일일지도 모른다. 예를 들어, 탐구된 가장 큰 Transformer는 100M 개의 파라미터를 가진 인코더를 포함해 (L=6, H=1024, A=16)이고, 우리가 문헌에서 찾은 가장 큰 Transformer는 235M개의 파라미터를 가진 (L=64, H=512, A=2)인 모델이다. 이와 대조적으로 $\mathbf{BERT_{BASE}}$ 는 110M개의 파라미터를 포함하고, $\mathbf{BERT_{LARGE}}$ 는 340M개의 파라미터를 포함한다.
기계 번역과 언어 모델링과 같은 큰 스케일의 작업에서 모델 사이즈를 키우는 것은 끊임없는 향상으로 이끈다고 알려진 지 오래됐으며, 이는 표 6에 나타난 제시된 훈련 데이터의 LM 복잡성에 의해 입증된다. 그러나, 모델이 충분히 사전 훈련을 진행한 경우, 극단적인 모델 크기로 확장이 매우 작은 규모의 작업에서도 큰 개선으로 이어진다는 것을 설득력 있게 입증하는 첫 작업이라고 생각한다. Peters 외 연구진은 사전 훈련된 bi-LM(양방향 언어 모델) 크기를 2개 층에서 4개 층으로 늘리는 다운스트림 작업 영향에 대해 엇갈린 결과를 제시했고, Melamud 외 연구진은 지나는 과정에서 은닉 상태를 200개에서 600개로 늘리는 것이 도움이 되었지만, 1,000개로 늘리는 것은 더 이상의 개선을 가져오지 못했다고 언급했다. 이러한 이전의 작업 모두 feature 기반 접근방식을 사용했다. 여기서 우리는 모델이 다운 스트림 과제에 맞게 미세 조정이 되어있고, 아주 적은 수의 무작위로 초기화된 추가적인 파라미터를 사용한다면, 다운 스트림 작업 데이터가 매우 작은 경우에도 과제에 특화된 모델은 더 크고 더 표현력이 뛰어난 사전 훈련된 표현으로부터 이익을 얻을 수 있다고 가정한다.
5.3 Feature-based Approach with BERT
지금까지 제시된 모든 BERT 결과는 사전 훈련된 모델에 간단한 분류 계층이 추가되고 모든 매개변수가 다운스트림 과제에서 공동으로 미세조정되는 미세 조정 접근법을 사용했다. 그러나 사전 훈련된 모델에서 고정된 특징을 추출하는 특징 기반 접근 방식은 확실한 장점이 있다.
-
모든 작업이 트랜스포머 인코더 구조에 쉽게 표현되는 것은 아니며, 그래서 과제별 모델 구조가 추가되어야 한다.
-
계산이 비싼 훈련 데이터의 표현을 한 번 사전 계산하는 것과 이러한 표현들의 위에 값싼 모델과 함께 많은 실험을 돌릴 수 있는 계산상의 큰 이익이 있다.
이 섹션에서, BERT에 두 가지 접근법을 도입해 CoNLL-2003 NER(Named Entity Recognition, 이름 명명 인식) 작업을 비교한다. BERT의 입력값으로 대소문자를 구별하는 WordPiece 모델을 사용하며, 우리는 데이터에 의해 제공되는 최대 문서 컨텍스트를 포함한다. 표준적인 관행에 따라, 우리는 이것을 태그 지정 작업으로 공식화 하지만, 출력에 CRF 레이어를 사용하지 않는다. 첫 번째 하위 토큰의 표현을 NER 라벨 세트를 통해 토큰 레벨 분류기에 대한 입력으로 사용한다.
미세 조정 접근 방식을 제거하기 위해, 우리는 BERT의 파라미터를 미세 조정하지 않고 하나 또는 그 이상의 레이어에서 활성화 함수를 추출하는 것으로 특징 기반 접근법을 적용한다. 이러한 문맥적인 임베딩은 분류 레이어 이전에 무작위로 초기화된 768차원의 BiLSTM 2개를 쌓은 레이어에 대한 입력으로 사용된다.
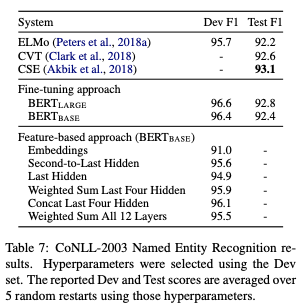
결과는 표 7에 표시되어있다. $\mathrm{BERT}_{\mathrm{LARGE}}$ 는 state-of-the-art 방법으로 경쟁력있게 수행한다. 가장 좋은 수행 방법은 사전 훈련된 트랜스포머의 4개의 은닉 레이어로부터 토큰 표현을 결합하는 것이며, 이것은 전체 모델을 미세 조정하는데 0.3 F1밖에 뒤지지 않는다. 이것은 BERT는 미세 조정과 특징 기반 접근법 모두 효과적이다라고 증명한다.
6. Conclusion
언어 모델과의 전이 학습으로 인한 최근의 경험적 개선은 풍부하고 지도하지 않는(비지도) 사전 훈련이 많은 언어 이해 시스템에 필수적인 부분을 보여주었다. 특히, 이러한 결과를 통해 낮은 수준의 작업도 깊은 단방향 아키텍처로부터 이익을 얻을 수 있다. 우리의 가장 큰 공헌은 이러한 연구 결과를 깊은 양방향 구조로 일반화하여 동일한 사전훈련 모델이 광범위한 NLP 과제를 성공적으로 처리할 수 있도록 하는 것이다.