다중 문장 분신술!
읽기 전에
학습 데이터가 부족한 상황에서 데이터를 변형시켜 그 양을 강제로 늘리는 기법을 데이터 증강(Data Augmentation) 이라고 한다. 보통 컴퓨터 비전에서는 활발하게 사용하고 있지만, 자연어 처리 분야에서는 단어 하나만 바뀌어도 문장의 의미가 전혀 달라지기 때문에 데이터 증강 기법을 활용하기가 쉽지 않았다.
2019년 EMNLP에서 발표된 EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks 논문은 그 어려운 것을 해냈다. 주요 내용은 자연어 처리에서 쉽게 떠올릴 수 있는 데이터 증강 테크닉이 실제로 성능 향상에 유의미한 영향을 미칠 수 있다는 것이었다.
항상 데이터가 부족해서 어디서 끌어와야하고 어떻게 하면 더 많은 데이터를 모을 수 있을까에 대한 고민을 했었는데 이러면 이 논문을 안볼 수가 없잖아. 읽어야지 그러면..
본문은 영어로 된 데이터를 증강하는 방법이기 때문에 한국어로 쓸 수 있는 방법은 여기에 구현해두었습니다.
참조한 사이트
- 논문
- 해당 논문의 깃헙 주소
-
항상 좋은 내용을 알기 쉽게 풀어서 써주신다.
Abstract
-
EDA: Easy Data Augmentation, 쉽게 데이터 증강하자! => 텍스트 분류 작업의 성능을 말 그대로 부스팅! 해줄 쉬운 데이터 증강
부스터어어어어~~! - 네 가지의 간단하지만 강력한 기법을 소개
- SR: Synonym Replacement, 특정 단어를 유의어로 교체
- RI: Random Insertion, 임의의 단어를 삽입
- RS: Random Swap, 문장 내 임의의 두 단어의 위치를 바꿈
- RD: Random Deletion: 임의의 단어를 삭제
- EDA가 합성망(Convolutional)과 순환신경망(RNN)에서 성능을 향상시킨다는 것을 보여주는데, 특히나 데이터가 적은 경우에 더 강력하다고 한다.
- 아무래도 데이터의 양이 많으면 노이즈를 생성시켜도 그 자체만으로는 큰 영향을 줄 수가 없으니, 어찌보면 당연하다고 생각한다.
- 데이터가 10개 있는데 5개를 추가하는 것은 그 데이터 집합의 성질을 바꾸기에 충분하지만 데이터가 10,000개가 있는데 5개를 추가하는 것은 그 자체만으로 데이터 집합의 성질을 바꿀 수가 없기 때문이다.
- 사용 가능한 훈련 데이터의 50%만 사용하면서 EDA를 사용한 학습과 100% 훈련 데이터로 학습한 것이 같은 정확도를 달성했다고…

호달달..
Introduction
텍스트 분류(Text Classification)은 자연어 처리의 정수라고 볼 수 있다. 그래서 머신러닝이나 딥러닝 모델들이 매번 정확도 검증하는게 sentiment analysis(감정 분류. 보통 긍정 or 부정 걸러냄)이나 topic classification(ex. 뉴스 기사 토픽 분류)를 많이 한다.
근데 높은 퍼포먼스는 보통 엄청난 양질의 데이터에 의존하는 경향이 있다. 컴퓨터 비전이나 음성에서는 훈련 데이터의 양이 적을 경우, 자동 데이터 증강(automatic data augmentation)해주는 걸 써서 모델을 더욱 견고하게 만드는 편이다(기존 데이터에서 자동 데이터 증강 기능을 사용하면 데이터 자체에 노이즈가 생기는 편이니 이를 학습해 더욱 모델이 견고해진다는 뜻이다). 컴퓨터 비전을 예로 들 경우, 이미지를 뒤집거나 각도를 조금씩 회전해 데이터를 변형시킨다.
개 이미지를 뒤집거나 각도를 조금 회전한다고 개가 아니게 되는 것은 아니기 때문에 어찌보면 데이터를 늘려도 퀄리티를 떨어뜨리진 않을 것이다.
그러나 자연어 처리에서는 이런 방식을 사용하기가 매우 힘들다. 단어의 뜻만 바뀌어도 문장의 의미 자체가 바뀌어버릴 수가 있기 때문이다. 이로 인해 NLP의 보편적인 데이터 증강 기법은 발전이 다른 분야에 비해 더뎠다.
이전에 제안되었던 유명한 자연어 처리 분야의 데이터 증강 기법에는
- 문장을 프랑스어로 번역하고 다시 영어로 번역해서 새로운 데이터를 얻어내는 방식.
- 데이터에 노이즈를 가볍게 주는 방식(data noising as smoothing)
- 유의어로 교체해주는 예측 언어 모델
이렇게 세 가지가 있다고 한다. 이런 테크닉들이 유효하긴 한데, 성능 대비 구현 비용이 높아서 잘 사용하진 않는다고 한다.
그래서 이 논문은 EDA라고 부르는 보편적인 데이터 증강 기법들을 소개하며, 자기들은 데이터 증강을 위한 텍스트 편집 기법을 포괄적으로 탐구한 최초의 사람 이라고 한다.
역시 이렇게 패기가 있어야 한다.
EDA를 다섯 가지 벤치마크를 통해 조직적으로 평가하고 얼마나 상당한 개선을 이루어냈는지, 특히(!) 적은 양의 데이터셋에 얼마나 도움을 주는지를 보여준다.
Particularly helpful for smaller dataset 이라는 문구를 상당히 자주 언급한다.
EDA
소규모 데이터 셋에 대해 학습된 텍스트 분류기의 쥐꼬리만한(measly라고 썼다 진짜) 성능에 실망했던 저자들은 컴퓨터 비전에서 사용되는 텍스트 분류기에서 약간의(loosely) 영감을 받아서 여러 가지 데이터 증강 작업을 테스트를 해봤는데 이게 도움이 크게 됐다고 한다.
EDA의 기법들에는 다음과 같은 것이 있다.
- 유의어로 교체(Synonym Replacement, SR): 문장에서 랜덤으로 stop words가 아닌 n 개의 단어들을 선택해 임의로 선택한 동의어들 중 하나로 바꾸는 기법.
- 랜덤 삽입(Random Insertion, RI): 문장 내에서 stop word를 제외한 나머지 단어들 중에서, 랜덤으로 선택한 단어의 동의어를 임의로 정한다. 그리고 동의어를 문장 내 임의의 자리에 넣는걸 n번 반복한다.
- 랜덤 교체(Random Swap, RS): 무작위로 문장 내에서 두 단어를 선택하고 위치를 바꾼다. 이것도 n번 반복
- 랜덤 삭제(Random Deletion, RD): 확률 p를 통해 문장 내에 있는 각 단어들을 랜덤하게 삭제한다.
긴 문장은 짧은 문장보다 단어가 많으니까, 원래의 라벨을 유지하면서 노이즈에 상대적으로 영향을 덜 받는다(can absorb more noise). 대신에 공식 $n = \alpha l$와 함께 문장 길이 $l$을 기준으로 SR, RI, RS에 대해 바뀐 단어의 수 $n$을 변화시킨다. 여기서 $\alpha$는 단어의 백분율이 변경되었음을 나타내는 매개변수 ($p = \alpha \text{ for RD}$).
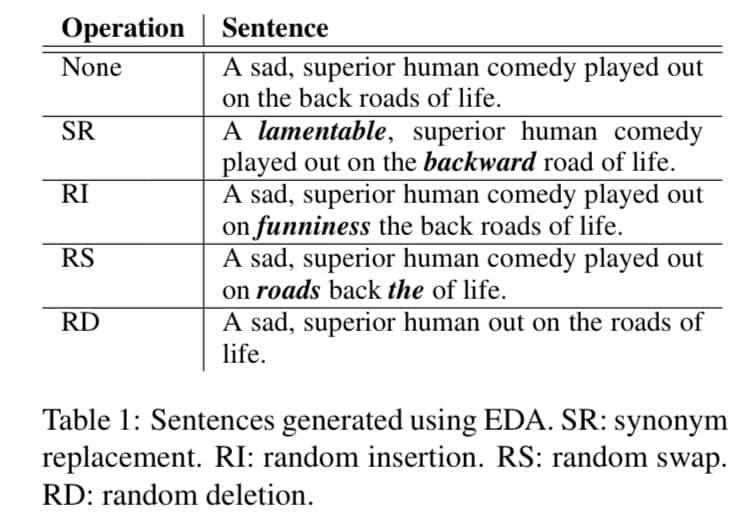
그리고 각각의 원래의 문장에 대해서 $n_{aug}$ 개의 증강된 문장을 만든다. 증강된 문장에 대한 예제는 표 1에 있다. 그리고 SR은 대체로 이전에 사용되었으나 나머지 RI, RS, RD는 이전에 연구가 안됐다고 한다.
Experimental Setup
이건 실험을 어떻게 했냐는 거니까 간략하게 언급만 하자면
- SST-2, CR, SUBJ, TREC, PC 등 다섯가지 벤치마크 텍스트 분류 작업을 했다고 한다.
- EDA가 더 작은 데이터 집합에 도움이 된다고 가정하고, 전체 교육 집합의 랜덤 부분 집합을 선택해 $N_{train}$ = {500, 2,000, 5,000, all avalilable data} 총 네 가지로 테스트를 진행함.
- 분류 모델로는 LSTM-RNN과 CNNs를 사용했다.
Result
EDA를 다섯 가지 NLP 과제에서 CNNs와 RNNs를 가지고 테스트했으며, 다섯 개의 랜덤 시드로부터 나온 결과의 평균을 냈다.
EDA Makes Gains
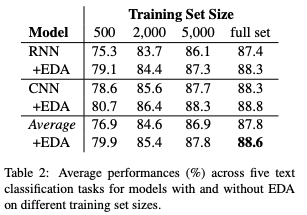
다양한 학습셋 크기에 대해 5개의 데이터셋에 걸쳐 EDA를 포함하거나 포함하지 않고 CNN과 RNN모델을 모두 실행했다고 한다. 성능에 대한 평균은 표 2에 작성했다. 평균적으로 전체 데이터셋을 사용할 경우 0.8%의 성능 향상이, $N_{train} = 500$ 일 때는 3.0% 정도 상승했다고 한다.
Training Set Sizing
오버피팅은 작은 데이터셋으로 훈련할 때 더 심해지는 경향이 있다. 그래서 데이터 셋을 몇 퍼센트 정도 쓰면서 EDA를 사용했을 때 정확도가 얼마나 더 상승하는지를 그래프로 나타냈다. 예상하다시피 기존 데이터셋의 비율이 적으면 EDA로 늘린 데이터셋과의 정확도 차이가 커지고, 기존 데이터셋의 비율이 커질수록 그 차이가 줄어든다.
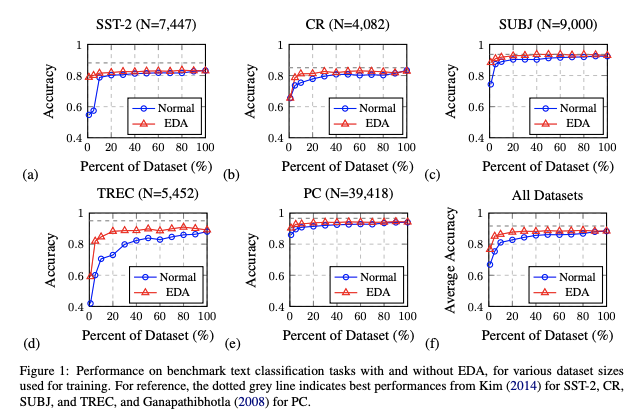
그래프를 보면 알겠지만 $N$ 사이즈 자체도 상당히 작은 편이다. 0~10% 사이대에서 EDA 활용 여부의 차이가 크다.
Does EDA conserve true labels?
어찌보면 제일 중요한 부분이다. 데이터셋을 늘린다고 늘렸는데 라벨이 훼손되면(기존의 라벨과 값이 다를 경우) 그건 쓸모가 없는 데이터셋이기 때문이다.
그래서 EDA를 사용하는 것이 새로 만들어낸 문장의 의미를 크게 변화시키는지에 대한 여부를 검토하기 위해서 시각화 접근법을 사용했다. 숫자로 보는 것보다 그래프로 보는 게 더 편하다는 뜻이다.
먼저 데이터 증강 없이 pro-con(긍부정과 같이 이진분류라고 생각하면 편함) 분류과제(PC)에 대해 RNN으로 훈련한다. 그런 다음, 시험 세트에 EDA를 적용하는데 문장 당 9개의 증강된 문장을 만든다. 이렇게 만든 문장을 원래 문장과 함께 RNN에 넣고, 마지막 레이어에서 결과물을 뽑아낸다. 이 값에 t-SNE를 적용하고 2-D 그래프로 나타낸다.
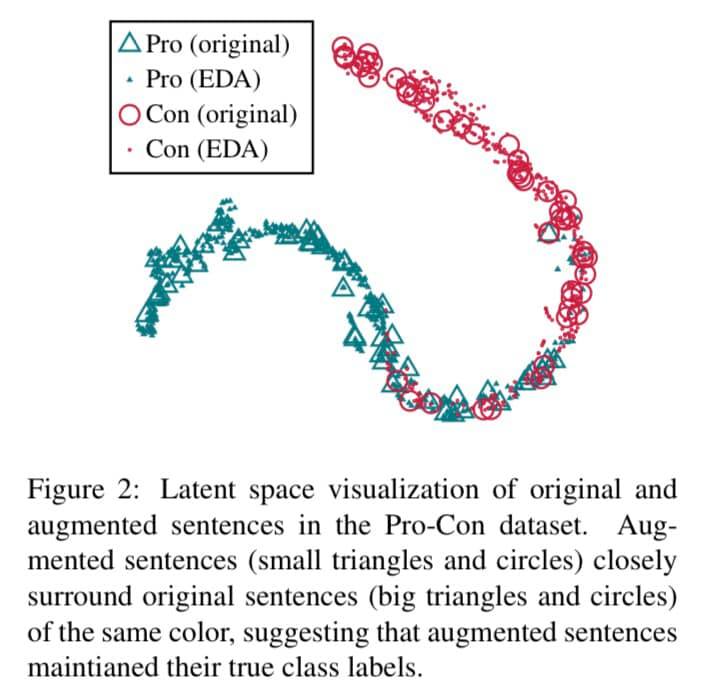
증강된 문장에 대한 그 결과의 잠재적인 공간표현들이 원래의 문장 공간표현들을 밀접하게 둘러싸고 있다는 것을 알아냈다 -> EDA로 증강된 문장들이 대부분 원래 문장의 라벨을 보존하고 있다!
Ablation Study: EDA Decomposed
c.f. Ablation Study
이게 없으면 전체 모델에 성능이 얼마나 떨어지지? 를 보는 실험이다.
EDA의 각 연산 효과를 알아보기 위한 Ablation Study를 실행했다. SR은 이미 이전에 연구되었지만, 다른 세 개의 EDA 연산들은 아직 탐구가 안됐다. EDA의 성능 이득의 대부분은 SR에서 나온 것이라고 가정할 수 있으므로, 각 EDA 연산을 분리해 테스트를 진행했다.
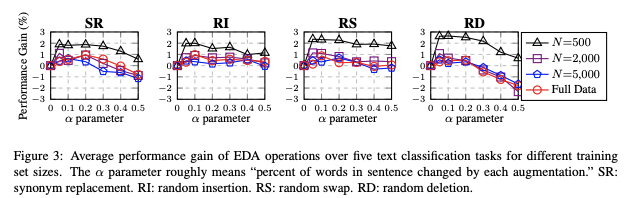
결과는 네 개 모두 성능 향상에 크게 기여하는 것으로 나타났다고 한다. SR은 $\alpha$가 작으면 성능 향상에 큰 도움이 되는데 $\alpha$가 크면 성능이 오히려 떨어진다. 너무 단어를 많이 바꾸면 문장의 의미(identity 라고 써놨는데 의미라고 의역했다)가 바뀌어서 그렇다고 한다.
RI는 $\alpha$ 값이 커질수록 성능이 안정적(!)으로 올랐다고 한다. 문장 내에 있는 원래의 단어와 그 관련된 순서들이 이 연산에서 유지가 되기 때문이다.
RS는 $\alpha \le 0.2$에서는 높은 성능을 얻을 수 있지만 $\alpha \ge 0.3$에서는 성능이 떨어진다. 많은 교환(swap)을 수행하는 것은 전체 문장의 순서를 바꾼 것과 동일하기 때문
RD는 $\alpha$가 작으면 높은 성능을 얻었는데 간간히 $\alpha$가 높았을 때 성능을 해쳤다. 문장 내에 단어들이 반 이상이나 삭제가 되면 당연히 문장을 이해할 수가 없기 때문
=> 모든 작업에 대한 소규모 데이터셋의 개선은 확실히 성능을 향상시켰으며, $\alpha = 0.1$일 때가 제일 성능이 좋았다(sweet spot).
How much augmentation?
그럼 한 문장 당 얼마나 증강을 하는게 좋을까? 아래 그림을 보면 문장 당 {1, 2, 4, 8, 16, 32} 개만큼 증강했을 때에 대한 결과를 보여준다.
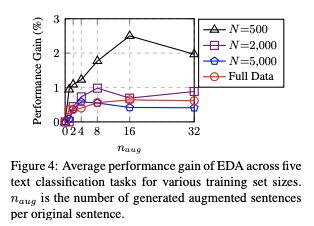
적은 훈련 셋에서는 오버피팅이 발생할 가능성이 더 높았기 때문에 문장을 많이 생성하면 더 큰 성능 향상을 얻을 수 있었다고 한다.
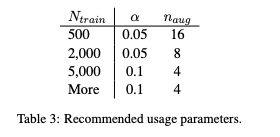
더 큰 훈련 세트의 경우, 많은 양의 실제 데이터를 사용할 수 있을 때 모델이 적절하게 일반화가 되는 경향이 있기 때문에 원래 문장당 4개 이상의 증강 문장을 추가하는 것은 도움이 되지 않는다. 이 결과에 기반하여 파라미터를 다음과 같이 추천한다.
Discussion and Limitations
이 논문은 향후 조사의 기준이 될 수 있는 일련의 간단한 연산을 도입함으로써(컴퓨터 비전에 비해) NLP의 표준화된 데이터 증강 기법의 부족을 해소하는 것을 목표로 했다.
NLP 연구의 비율이 최근 많이 늘었으며, 연구자들이 곧 사용하기 쉬운 더 높은 성능의 데이터 증강 기술이 나올 것이라고 기대한다. 최근 NLP 연구의 대부분이 크거나 더 복잡한 신경망 모델을 만드는데 집중이 되어있지만 이 연구는 정반대로 접근한다. 이에 대한 질문이 라벨 손상 없이 어떻게 문장을 만들어낼 수 있을까? 다. EDA가 현재나 미래에 NLP를 위한 데이터 증강 기법이 될 것이라고 예상하지 않지만, 대신에 보편적이나 작업별 데이터 증강에 대한 새로운 접근법에 대한 영감을 주었길 희망한다고 한다.
한계점에 대해서 이야기해보자면, 역시나 데이터가 충분할 때 성능적으로 이득이 제한적일 수 있다는 것이다. 앞서 실험한 다섯 가지 벤치마크에서 모든 데이터를 사용하고 여기에 EDA를 적용했을 경우 정확도가 1% 올랐다고 한다.
이미 충분하니까..
그리고 작은 데이터셋에서 더 좋은 성능을 얻는 건 명백한데, 사전 훈련된 모델을 사용하는 경우에는 상당한 개선 효과를 거두지 못할 수도 있다고 한다. ULMFit이나 ELMo, BERT같은 모델에서는 무시할 수 있는 수준이라고…
마지막으로 다섯가지 벤치마크 데이터셋에서 평가했지만, NLP의 데이터 증강에 대한 다른 연구는 다른 모델과 다른 데이터셋을 사용하므로 관련 작업과의 공정한 비교는 매우 비현실적이다.
Conclusion
간단한 데이터 증강 연산은 텍스트 분류에 큰 도움이 된다. 물론 무조건 잘된다!는 아니지만 소규모 데이터셋에 대한 학습을 진행할 때 성능을 실질적으로 향상시키고 오버피팅을 감소시킨다.
요약하자면
- 텍스트 데이터 증강에 사용된 기법은
- 특정 단어를 유의어로 교체하는 SR
- 임의의 단어를 삽입하거나 삭제하는 RI, RD
- 문장 내 임의의 두 단어의 위치를 바꾸는 RS
-
SR은 충분히 상식선에서 이해가 되는데, RI, RD, RS는 의외로 원문의 라벨 성질을 대체로 잘 따른다 는 결과가 나왔다.
- 심지어 노이즈를 적절히 만들어줘서 기존에 데이터가 부족해 오버피팅이 나는 현상을 어느 정도 억제해준다고 한다.