![[논문 뽀개기] ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORSComplexities](https://cdn.pixabay.com/photo/2016/08/02/21/18/pepperoni-1565029_960_720.jpg)
작은 고추가 더 맵다
읽기 전에
ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately)는 BERT의 MLM(Masked Language Model) 과제를 사전훈련할 때 상당히 많은 계산량이 필요한 것과 대비해 적은 리소스로도 충분히 좋은 성능을 낼 수 있는 모델이다. 이 모델은 Replaced Token Detection(RTD)라는 새로운 사전 훈련 과제를 제시하며 BERT, GPT보다 작은 리소스를 가지고도(only 1 GPU!) 성능을 능가하는 모델이다.
참고한 사이트
1. Introduction
현재 언어 표현 학습 기법에 대한 SOTA는 denoising autoencoder 학습으로 볼 수 있다. 이 학습 방법은 라벨이 붙지 않은 입력 시퀀스의 작은 집합(보통 15%)을 선택하고, 이 토큰들의 정보를 마스킹하거나(BERT) 그 토큰에 좀 더 집중하며(XLNet) 원래의 입력을 알아내기 위해 네트워크를 훈련한다. 양방향 표현 학습을 하기 때문에 Convolutional 언어 모델 사전 훈련에 비해서 더 효과적이지만, MLM 접근 방법은 네트워크가 예제 토큰의 15%만을 학습하기 때문에 상당한 계산 비용이 발생한다.
왜 상당한 계산 비용이 발생하느냐
- 위에서 전체 토큰의 15%만 학습한다고 했는데 이는 다시 말하면 전체의 15%에 대해서만 손실함수를 사용하는 것이기 때문에 더 많은 학습을 진행해야 한다는 것.
- 그렇기 때문에 학습 비용이 추가적으로 늘어난다.
이에 대한 대안으로서 사전 훈련 작업인 replaced token detection을 제안하는데, 모델이 그럴듯하지만 합성적으로 생성된 대체물로부터 실제 토큰을 구별할 수 있도록 학습한다. 마스킹 대신에, 이 방법은 특정 단어의 샘플로 일부 토큰을 대체함으로서 입력을 변형(corrupt)시키는데, 이것은 전형적으로 작은 MLM의 결과물이다. 이러한 변형 절차(corruption procedure)는 네트워크가 인공적으로 만든 MASK 토큰을 다운스트림 과제의 미세조정할 때가 아니라 사전훈련할 때 보기 때문에 생기는 BERT(XLNet은 아니지만)의 미스매치를 해결해준다.
미스매치?
- BERT는 사전 훈련때 [MASK] 토큰을 만드는데, 실제 데이터에는 [MASK] 토큰이 없기 때문에 미스매치가 발생한다!
그리고 네트워크를 모든 토큰이 오리지널인지 교체된 것인지에 대해 예측하는 discriminator로써 사전훈련한다. 이와 대조적으로 MLM은 변형된 토큰의 원래 ID를 예측하는 generator로 네트워크를 훈련시킨다. 판별 작업의 가장 큰 장점은 모델이 작은 마스킹된 집합 대신 모든 입력 토큰을 학습한다는 것이며, 이것은 계산적으로 효과적이게 만든다. 비록 이 접근은 GAN의 판별 훈련과 비슷하지만(reminiscent) 이 방법은 변형된 토큰을 생산하는 generator가 텍스트에 GAN을 적용하기 어렵기 때문에 최대가능우도(Maximum likelhood)로 훈련된다는 점에서 적대적(adversarial)이지 않다.
이런 접근법을 ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately)라고 부른다(직역하면 토큰 교체를 정확하게 분류하는 인코더를 효율적으로 학습). 이전의 연구에서와 같이 다운스트림 작업에서 미세조정 될 수 있는 사전 훈련시킨 Transformer 텍스트 인코더에 적용한다. 일련의 ablation들을 거쳐, ELECTRA가 완전히 훈련됐을 때 다운스트림 과제에서 높은 정확도를 달성한다는 것을 보여준다.
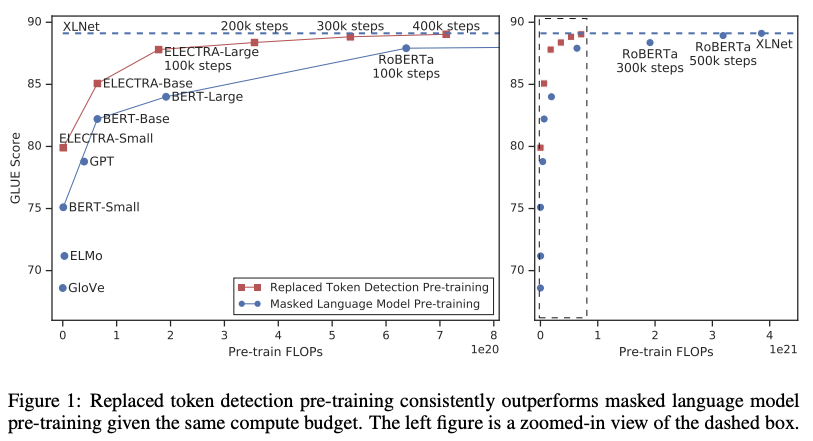
최근 사전 훈련 방법들은 많은 양의 연산이 효과적이어야 하므로 비용과 접근성에 대한 우려가 제기된다. 더 많은 연산을 하는 사전 훈련은 거의 항상 더 나은 다운스트림 정확도들로 결과가 나타나기 때문에, 우리는 사전 교육 방법에 대한 중요한 고려사항은 절대 다운스트림 성능 뿐만 아니라 계산 효율성이어야 한다고 주장한다. 이런 관점에 따라 우리는 다양한 사이즈의 ELECTRA 모델을 훈련하고, 이 모델들의 연산 요구량 대비 다운스트림 성능을 평가한다. 특히 우리는 GLUE 자연어 이해 벤치마크와 SQuAD 질문 답변 벤치마크를 가지고 실험한다. ELECTRA는 같은 모델 사이즈, 데이터, 연산량이 주어졌을 때, MLM 기반 방법인 BERT와 XLNet보다 뛰어난 성능을 보여준다(figure 1 참고). 예를 들어 ELECTRA-Small은 1개의 GPU를 가지고 4일동안 훈련시켜서 만들 수 있었다. ELECTRA-Small 은 작은 BERT모델(BERT base 모델인 듯)대비 GLUE에서 5점 높고, 더 큰 모델인 GPT보다도 성능이 높다. 우리의 접근 방법은 또한 큰 사이즈에서도 잘 작동하며, 여기서 우리는 매개변수가 적고 훈련에 컴퓨팅에 1/4를 사용함에도 불구하고 RoBERTa와 XLNet에 견줄만한 ELECTRA-Large모델을 훈련한다. ELECTRA-Large 훈련은 GLUE에서 ALBERT를 능가하는 더욱 강력한 모델을 만들어 내고, SQuAD 2.0에서 새로운 SOTA를 달성한다. 종합해보면, 부정적인 샘플로부터 진짜 데이터를 구별해내는 차별적인 작업에 대한 우리의 결과는 기존에 존재하던 언어 표현 학습의 생성적 접근보다 연산과 파라미터에 효율적이라는 것을 가리킨다.
2. Method
먼저 교체된 토큰 탐지 사전 훈련 작업을 작성한다. Figure 2에 요약되어있다. 섹션 3.2에서 이 방법에 대한 몇 가지 모델링 개선을 제안하고 평가한다.
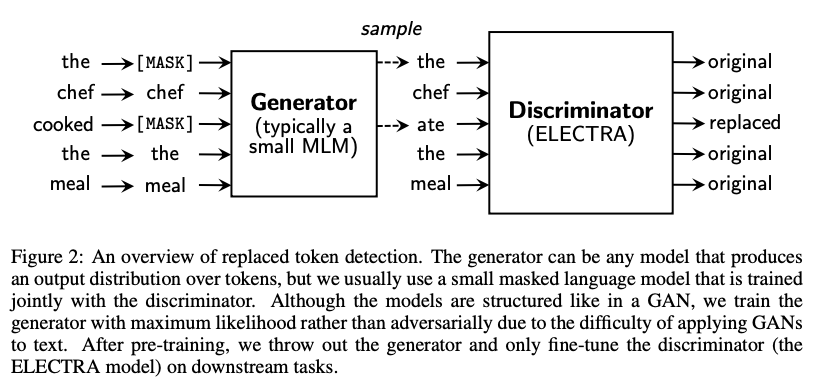
우리의 접근법은 generator G와 discriminator D, 두 개의 뉴럴 네트워크를 훈련한다. 각각 일차적으로 입력 토큰 $x = [x_1, \cdots, x_n]$의 시퀀스를 문맥에 맞는 벡터 표현 시퀀스 $h(x) = [h_1, \cdots, h_n]$에 매핑하는 인코더(예를 들면 트랜스포머 네트워크)로 구성되어 있다. 위치 $t$가 주어졌을 때(우리의 경우 $x_t = [\text{MASK}]$인 위치만 해당), generator는 소프트맥스 레이어에서 특정 토큰 $x_t$를 생성할 확률을 출력한다.
\[p_G(x_t|x) = \text{exp}(e(x_t)^T h_G(x)_t) / \sum_{x'} \text{exp}(e(x')^T h_G(x)_t)\]여기서 $e$는 토큰 임베딩을 나타낸다. 위치 $t$가 주어졌을 때 discriminator는 토큰 $x_t$가 “진짜” 인지, 즉 시그모이드 출력 레이어를 가진 generator 분포가 아닌 데이터에서 나온 것인지 예측한다.
\[D(x, t) = \text{sigmoid}(w^T h_D (x)_t)\]generator는 MLM을 수행하기 위해 훈련된다. 입력 $x = [x_1, x_2, \cdots, x_n]$이 주어졌을 때, MLM은 임의의 위치 집합(정수이며, 1과 $n$ 사이)을 먼저 선택한 뒤, $m = [m_1, \cdots, m_k]$로 마스킹 시킨다(여기서 K는 전통적으로 $[0.15n], 즉 15%의 토큰을 마스킹한다.$). 선택된 위치들의 토큰들은 $[\text{MASK}]$ 토큰으로 교체된다. 우리는 이걸 $x^{\text{masked}} = \text{REPLACE}(x, m, [\text{MASK}])$로 나타낸다. generator는 그 다음 마스킹된 토큰의 원래 정보를 예측하기 위해 학습한다. discriminator는 데이터의 토큰과 generator의 샘플로 대체된 토큰을 구별하기 위해 훈련된다. 좀 더 구체적으로 말하자면, 우리는 마스킹된 토큰을 generator 샘플로 교체하여 변형된 예제 $x^{\text{corrupt}}$를 생성하고, $x^{\text{corrupt}}$가 원래의 입력 $x$가 맞는지 예측하기 위해 discriminator를 훈련한다. 정식으로, 모델 입력은 다음을 따라 만들어진다.
\[m_i \sim \text{unif} \{1, n\} \text{ for } i = 1 \text { to } k \qquad x^{\text{masked}} = \text{REPLACE}(x, m, [\text{MASK}] \\ \hat{x}_i \sim p_G(x_i|x^{\text{masked}}) \text{ for } i \in m \qquad x^{\text{corrupt}} = \text{REPLACE}(x, m, \hat{x})\]그리고 손실 함수는
\[\mathcal{L}_{\text{MLM}}(\textbf{x}, \theta_G) = \mathbb{E} \left( \sum_{i \in \textbf{m}} -\log p_G (x_i | \textbf{x}^{masked}) \right)\] \[\mathcal{L}_{Disc} (\textbf{x}, \theta_{D}) = \mathbb{E} \left( \sum_{t=1}^{n} -\mathbb{1}(x_{t}^{corrupt} = x_t) \log D(\textbf{x}^{corrupt}, t) - \mathbb{1}(x_{t}^{corrupt} \neq x_t) \log (1-D(\textbf{x}^{corrupt}, t)) \right)\]비록 GAN의 훈련 목적과 비슷해보이나 몇 가지 중요한 차이가 있다. 먼저 generator가 우연히 올바른 토큰을 생성해냈다면, 토큰은 ‘가짜’ 대신 ‘진짜’ 로 고려된다. 우리는 이 공식으로 다운스트림 작업에 대한 결과를 적당히 향상시킬 수 있다는 것을 발견했다. 더 중요한 것은, generator는 discriminator를 속이기 위해 적대적으로 훈련받는 것 대신 MLH로 훈련된다. 적대적 훈련은 generator에서 샘플링을 통해 backpropagate 하는 것이 불가능하기 때문에 힘들다. 비록 generator를 훈련하기 위해 강화학습을 사용하는 것으로 이 이슈를 우회적인 방법으로 실험했지만, 이 방법은 MLH보다 성능이 낮았다. 마지막으로 우리는 GAN에서 전형적으로 사용하는 noise vector를 generator에 공급하지 않는다.
손실함수를 결합해 최소화하면
\[\min_{\theta_G, \theta_D} \sum_{x \in \mathcal{X}} \mathcal{L}_{\text{MLM}}(x, \theta_G) + \lambda\mathcal{L}_{\text{Disc}}(x, \theta_D)\]로 표현할 수 있다. $\mathcal{X}$는 raw text. 우리는 하나의 표본으로 손실에 대한 기대치를 대략적으로 계산한다. generator를 통해 discriminator의 손실을 역전파로 계산하지 않는다(사실 못한다. 샘플링 스텝 때문에). 사전 훈련 후에, generator는 버리고 discriminator를 다운스트림 과제에서 미세 조정한다.
3. Experiments
3.1 Experimnetal Setup
GLUE(General Language Understanding Evaluation) 벤치마크와 SQuAD(Stanforn Question Answering) 데이터셋을 가지고 평가했다. GLUE는 textual entailment (RTE and MNLI), question-answer entailment (QNLI), paraphrase (MRPC), question paraphrase (QQP), textual similarity (STS), sentiment (SST) 그리고 linguistic acceptability (CoLA) 를 커버하는 다양한 과제들을 포함한다. GLUE 과제에 대한 세부사항은 부록 C를 참고. 우리의 측정 기준은 STS에는 스피어맨 상관계수, CoLA에는 매튜 상관계수, 그리고 다른 GLUE 과제는 정확도로 평가한다. 모든 과제들은 평균을 내서 리포트한다.